namakemono
🦥 namakemono = Sloth (Japanese) = Slow and forgetful = very delay-tolerant, offline-first and privacy-respecting 🩷
namakemono is a protocol for peer-to-peer and federated applications. It gives them sloth-superpowers: offline-first collaboration, fine-grained permissions, data validation, schema migration, decentralised group encryption, low memory footprint, efficient replication and privacy-respecting deletion.
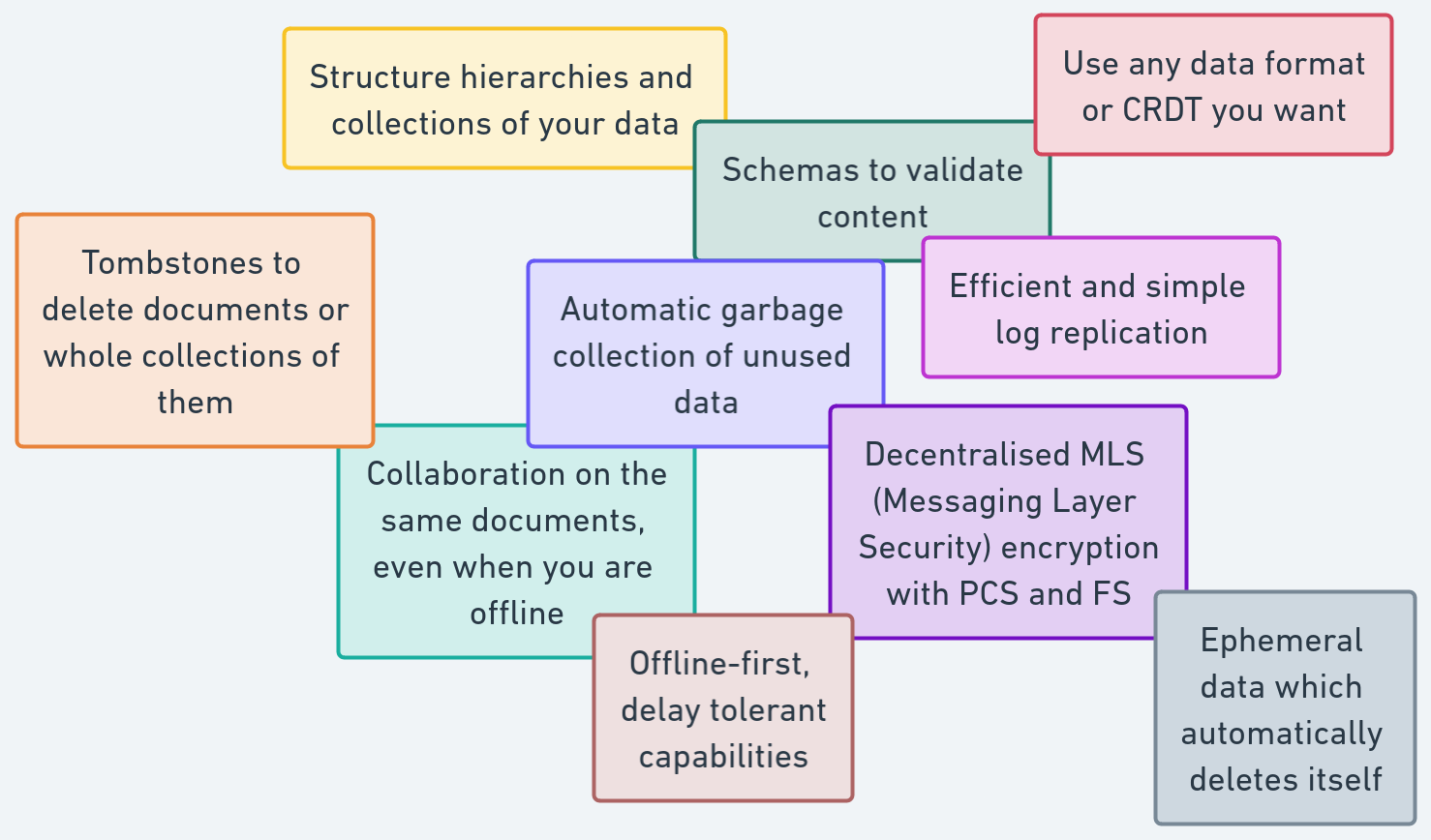
namakemono was designed to solve common privacy- and efficiency problems when building collaborative applications in peer-to-peer systems. This includes:
- Offline-first collaboration: Create and edit data with others, even when you're offline. Distributed systems usually compromise on "how long" you can be offline, namakemono gives you the tools to stay offline as long as you want
- Fine-grained capabilities: Full control over your data by defining who can sync, create, update or delete what. Usually capability system require nodes to be online, namakemono allows capabilities to be offline-first
- End-to-end encryption: Secure group encryption with PCS and FS
- Don't grow data forever, except if you want to: Keep the history of all changes if you need them, or delete old data instantly when your application does not require it, even of other authors
- Hybrid networks: Use namakemono in both peer-to-peer or federated networks, or even both of them at the same time
- Privacy-respecting deletion: Delete whole collections of data with one tombstone or let data disappear by itself, giving it an expiry date
- Schemas: Define and distribute versioned and migratable schemas of your choice to validate incoming data
- Collections: Structure hierarchies of data collections, combining them with permissions to model user-roles, moderation, admin access and more typical application concerns
- Re-use your key-pair: .. on multiple devices without being afraid of accidental forks
- Efficient and partial sync: namakemono is still a linked-list and can leverage from fast, simple and efficient log-replication
- Flexible: Use any CRDT, database, transport, data validation format, encoding, digital signature algorithm or hashing algorithm you want!
namakemono is based on the original p2panda specification and can be seen as the next, simplified iteration. It helps us to leverage from the best parts we've came up with so far over the last years, separate application concerns more from the protocol ("bring your own CRDT") and remove the Bamboo append-only log data type (as we realized we haven't used it in the form it was designed for).
If you have any comments or feedback on this specification. Please contact us!
Short overview

Encoding & Cryptographic Primitives
- Namakemono works theoretically with any data encoding, digital signature algorithm (DSA) or hashing algorithm
- We recommend Ed25519 for signatures, BLAKE3 for hashing and CBOR for encoding
Documents
- Documents is how we distinguish one piece of data from another
- Documents are created and changed with Operations, each operation changes the state of a document
- The first operation determines the beginning of a new document
- Any other operation which is part of the same document changes its state
- Many authors can contribute to one document
Operations
- Every item in the linked-list is called an Operation
- An operation consists of a Header and a Body
- The header contains always the following fields:
struct Header {
/// Version of the operation format, currently `1`
version: u64,
/// Digital signature of this operation, p2panda uses Ed25519
signature: Signature,
/// Public key of the author of this operation
public_key: PublicKey,
/// Hash of the body of this operation, can be omitted if no body is given
payload_hash: Option<Hash>,
/// Number of bytes of the body of this operation, can be omitted if no body is given
payload_size: Option<u64>,
/// UNIX timestamp. If not the first operation in the document it needs to
/// be larger or equal than the timestamp the operation points at via it's
/// `backlink` or `previous` link (see below)
timestamp: u64,
/// Number of operations this author has published to this document, begins
/// with `0` and is always incremented by `1` with each new operation by the
/// same author
seq_num: u64,
} - The Body is not further defined, it can be any arbitrary bytes
struct Body(Vec<u8>) - Since the header is stored separately from the body, the body can be deleted at any point without any consequences for the data type
Creating documents
- As soon as an operation is published it is considered a CREATE operation. CREATE operations define a new document
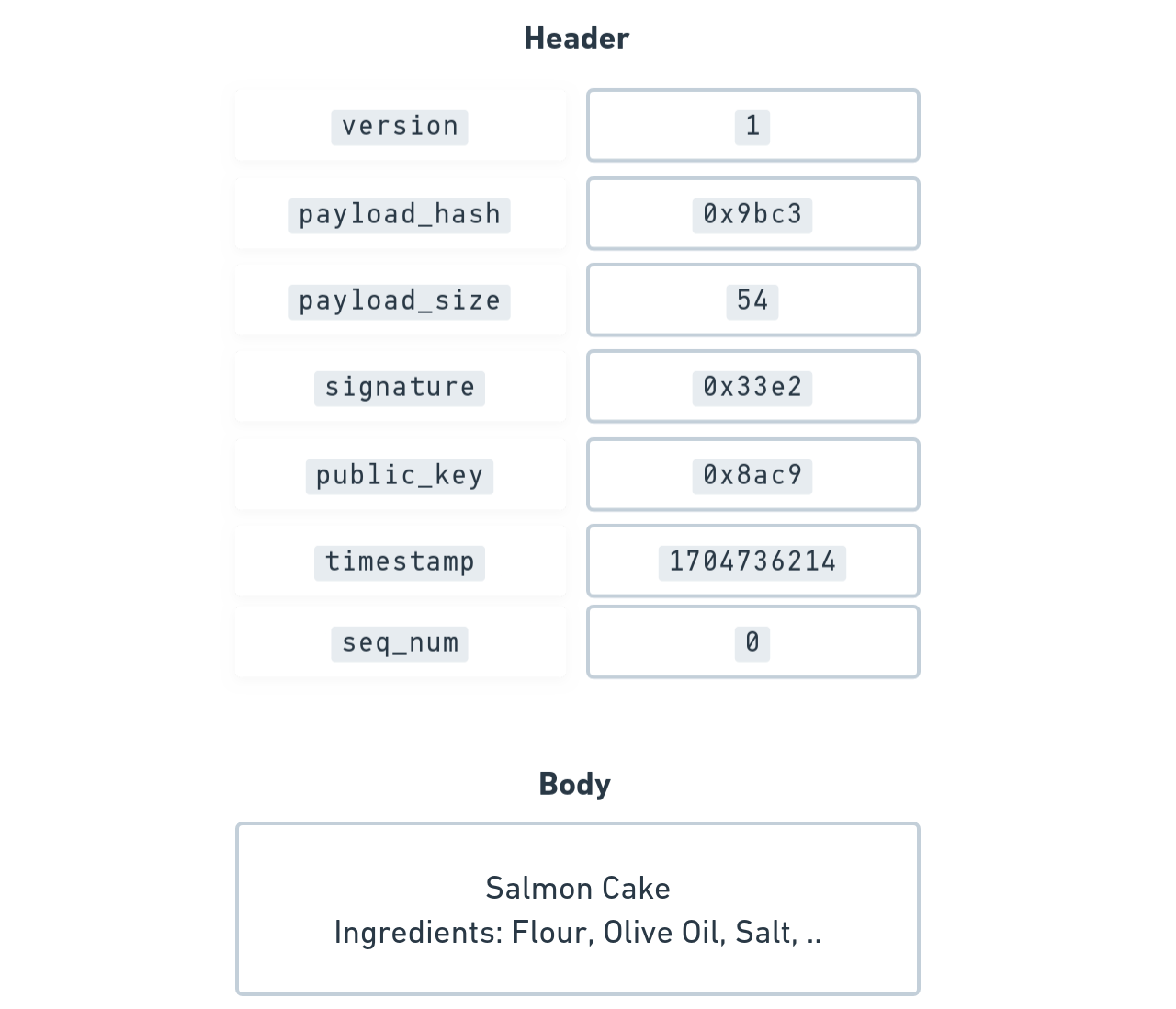 Creating a new Salmon Cake recipe document with a CREATE operation
Creating a new Salmon Cake recipe document with a CREATE operation - The hash of this CREATE operation is used as the identifier of the whole document for its entire lifetime
 Generating a hash from the operation header
Generating a hash from the operation header - This header of the CREATE operation should be kept for the lifetime of it's document, its signature is the proof of authorship for the owner (the owner can delegate capabilities later)
Updating documents
- If we want to refer to this document with another UPDATE operation, changing the state of a document, we add the following fields to the header:
struct Header {
/// Hash of the previous operation of the same author
backlink: Hash,
/// Hash of the CREATE operation aka "document ID" we refer to with this update
document_id: Hash,
// ... plus same fields as above
} - The
seq_numneeds to be incremented by1and the operation is appended to the author's log for this document
Collaboration
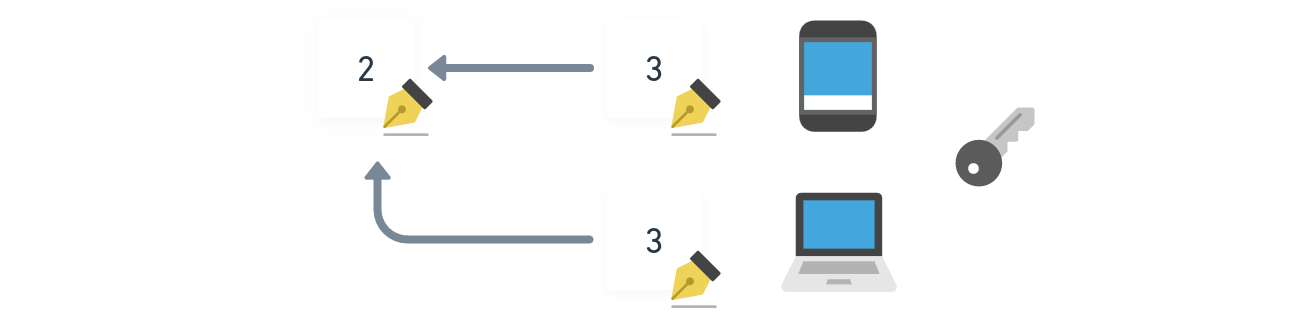
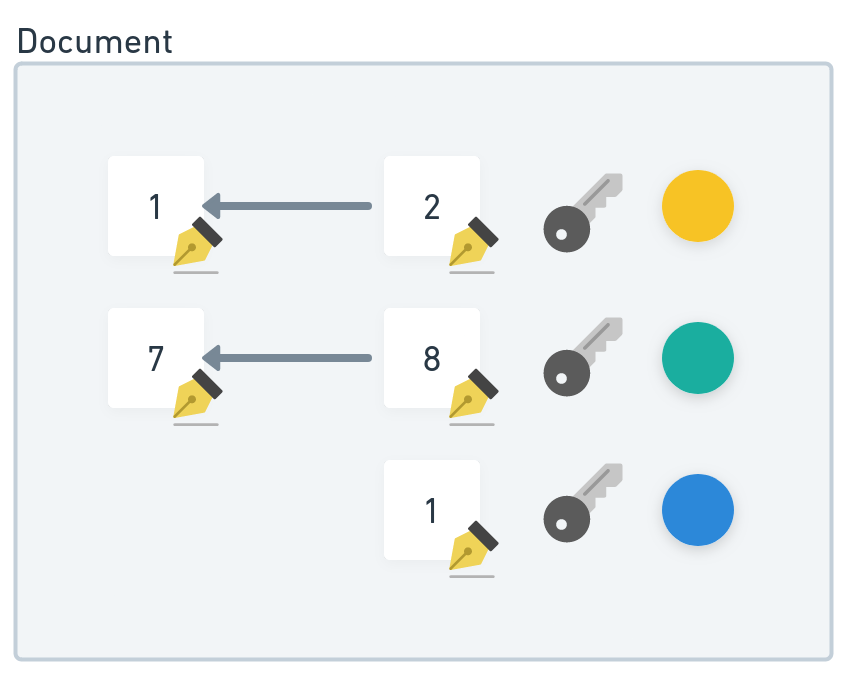
- If multiple users want to write to the same document, they refer to the same
document_idwhen publishing UPDATE operations - Here we have three different authors (Blue, Orange, Yellow) writing to the same document with ID
0x2bacwhich was created by Blue: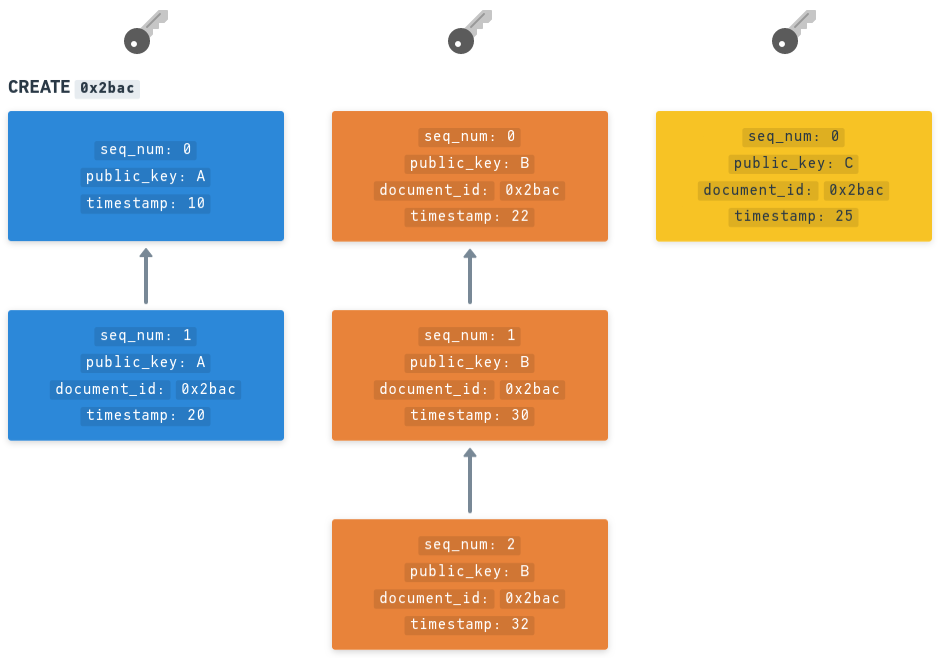 Writing to the same document which was created by the Blue author
Writing to the same document which was created by the Blue author - By default it is not permitted to write to any document if you're not the original author. Through "Capabilities" we can add more authors, giving them the permission to write to your documents
Ordering
- We need a way to determine which operations took place before others when collaborating on the same document
- Through adding
previouslinks in the operation header we can determine a causal order of which operations were created before others (similar to vector clocks):struct Header {
/// Optional list of hashes of the operations we refer to as the
/// "previous" ones. These are operations from other authors
previous: Option<Hash[]>,
// ... plus same fields as above
} - We apply a topological sorting algorithm on top of the DAG formed by the
previouslinks to determine this ordering - This algorithm sorts all operations of all authors from "earliest" to "latest", the last operation in this sorted list is the "last" write
- Using
previouslinks is optional as it depends on the application if this level of cryptographic security over ordering is required. - When using
previouslinks thetimestampfields become more secure as it is not allowed to publish an earlier timestamp than the previous one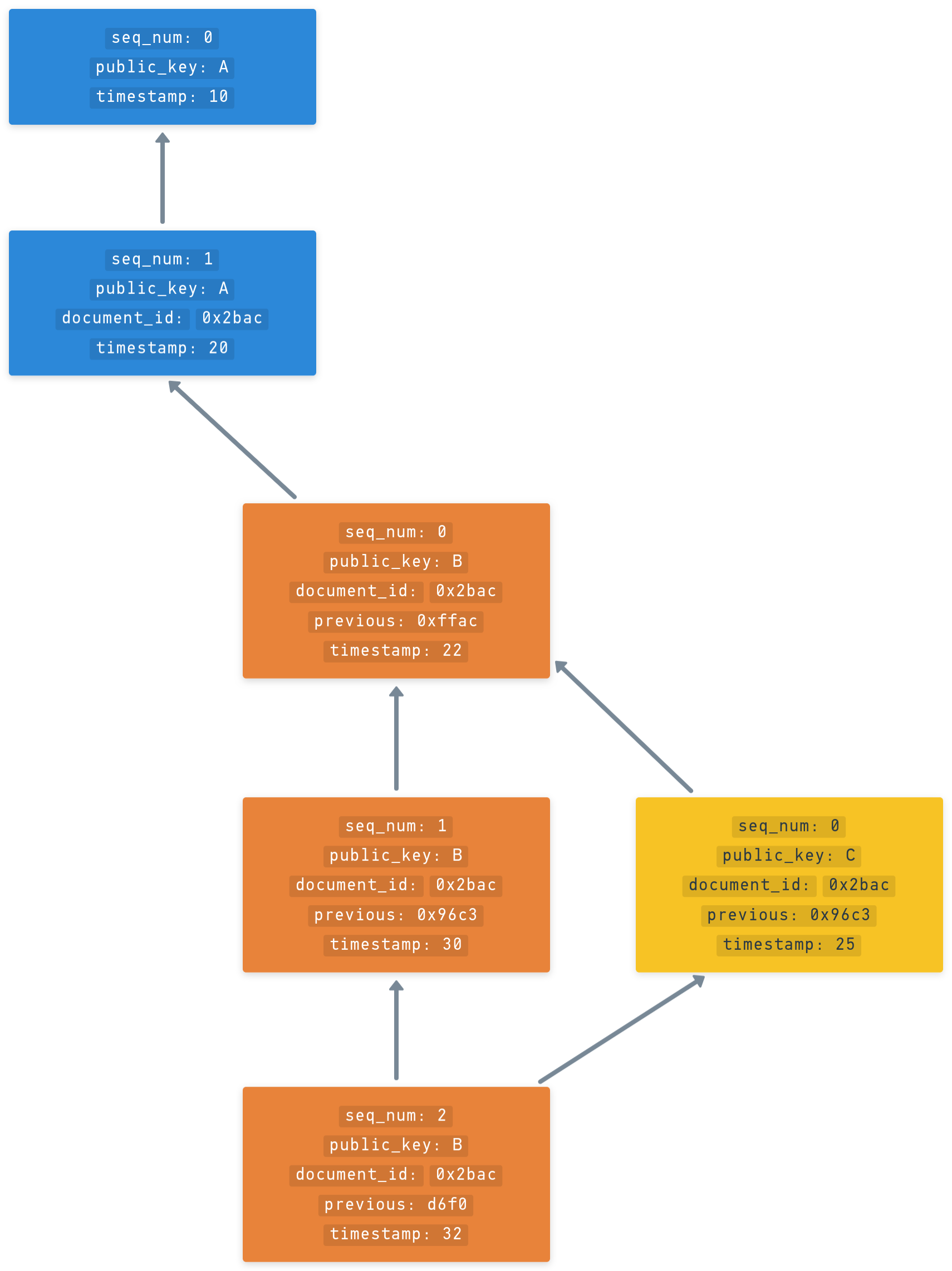 Ordering operations of a document by previous links
Ordering operations of a document by previous links - If no
previouslinks have been given thetimestampis used to determine the ordering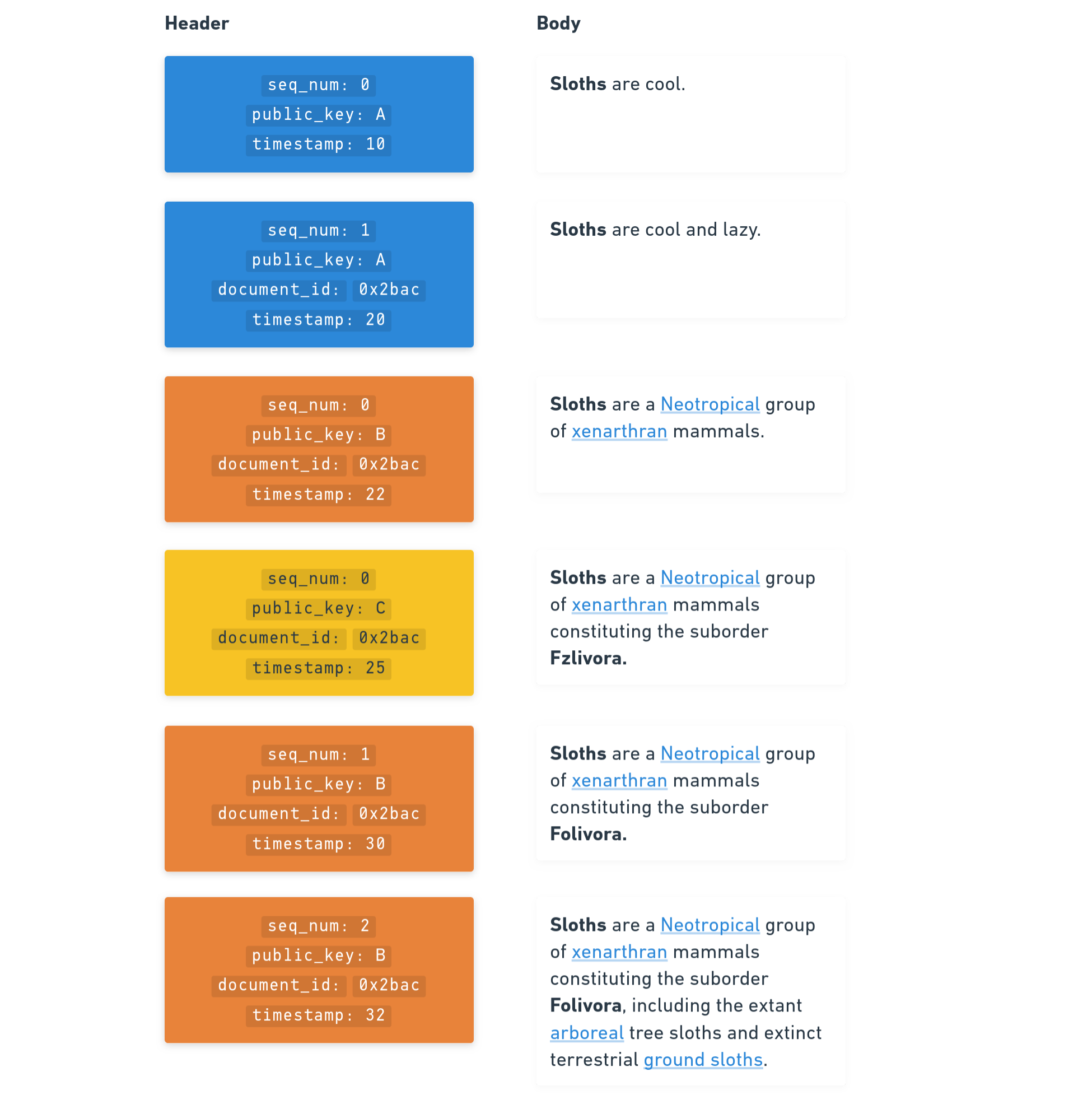 Ordering operations of a document by timestamp
Ordering operations of a document by timestamp
Views
- Document views represent the immutable state of a document at a particular point in its history of edits
- Every change of a document results in a new document view
- A document view is identified by its set of graph tips: the document view id
- Each graph tip is represented as an operation id
- It's possible to replicate the exact state of a document from the document view id, as long as the history was preserved
- Document views are required for
previouslinks, extensions, like capabilities or encryption
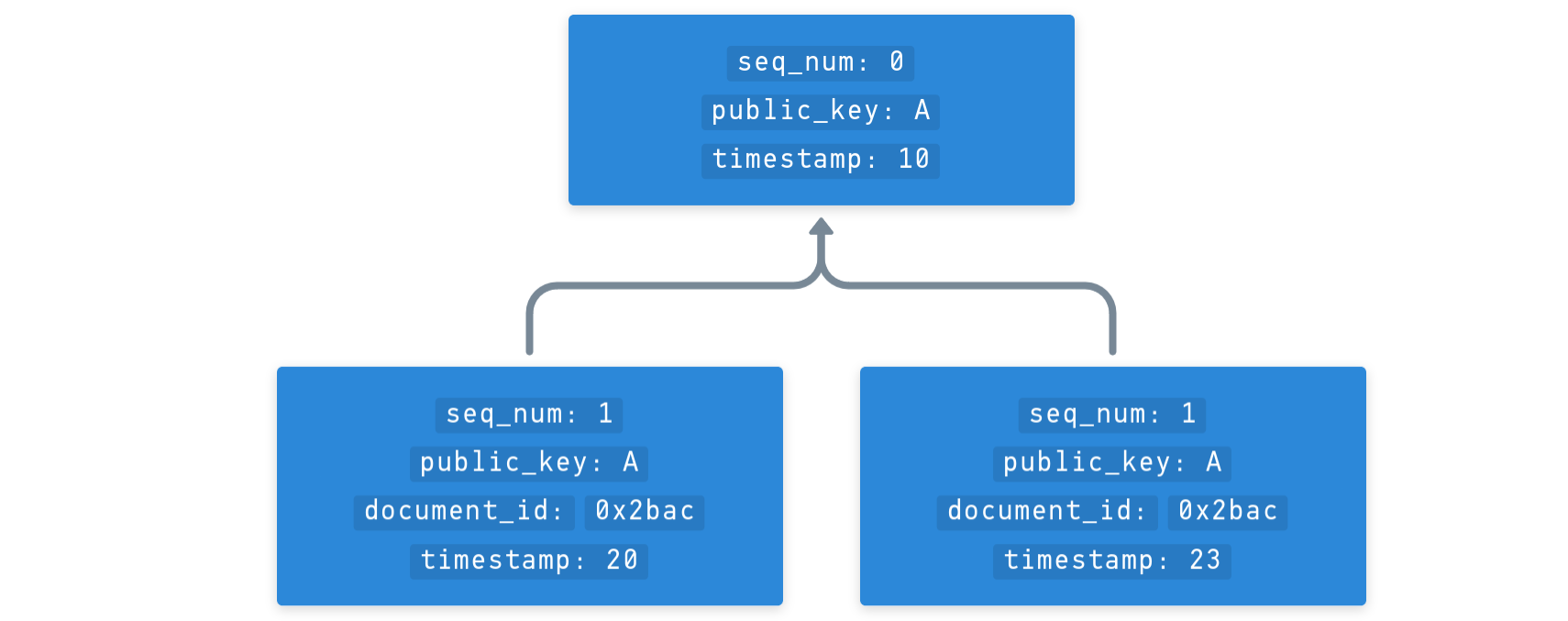
Forks
- If a peer observes duplicate
backlinkand / orseq_numfields, thetimestampis picked as a tie-breaker, if thetimestampis the same, the hash of the operation (operation ID) is picked as a tie-breaker, with the higher hash winning - Accidental forks are not considered harmful to the system and can usually be resolved easily
- Forks by malicious authors need to be actively managed and removed by the application using the capabilities system (see more under "Capabilities"), authors are always explicitly granted permission to contribute to a document, they can be removed after malicious behaviour was noticed
History
- The latest operations (see "Ordering") of the set determine the latest state of the document
- Documents can contain the history of their changes by preserving older operations
- It is possible to retain all history, or just the latest
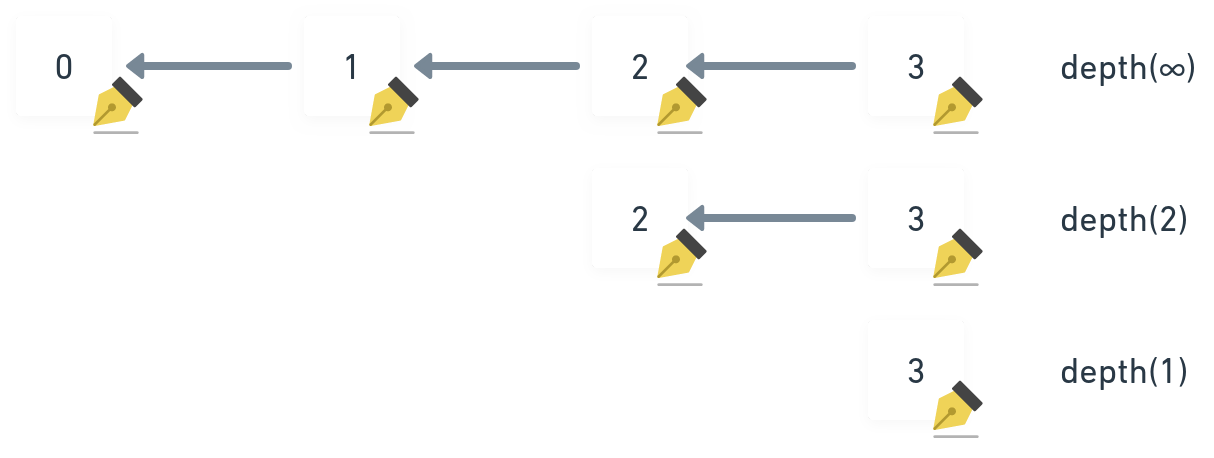
noperations for a document- Shallow documents: only keep the latest
noperations- As new operations arrive from each author, they replace older versions, these older operations can be garbage collected
- In this case causal ordering (
previouslinks) between operations is sometimes lost and operation ordering falls-back to usingtimestamp
- Deep documents: keep all causal history back to the document's CREATE operation
- This guarantees accurate, delay-tolerant ordering of operations
- Garbage collection can still be performed on the body of operations
- Headers are retained for the lifetime of the document
- Shallow documents: only keep the latest
- Depending on the applications requirements documents with a "longer" history can securely guarantee ordering through the
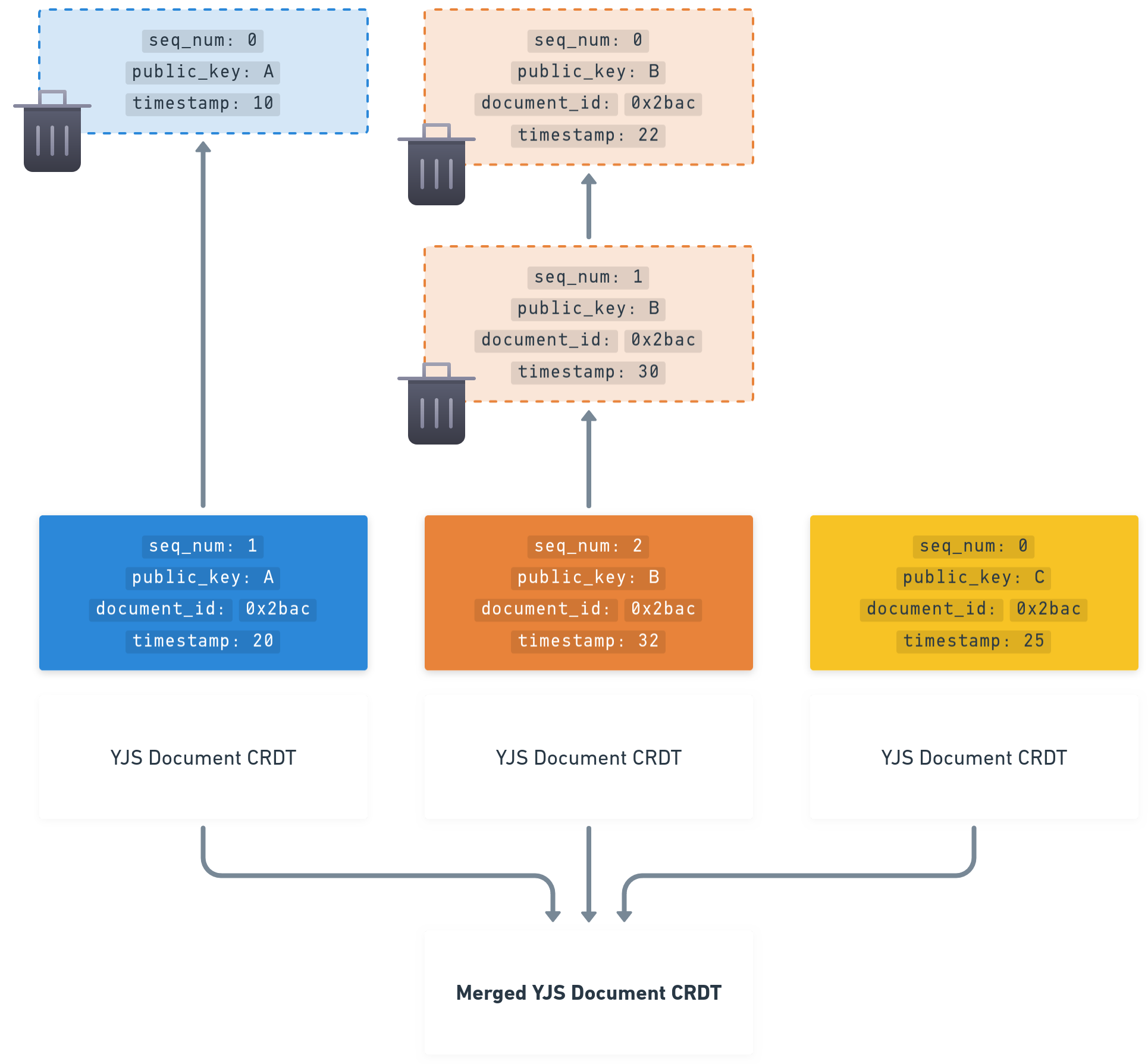
previouslinks while more shallow documents need to rely more on insecure / forgeable timestamps - Example: Using a CRDT into the operation body (like YJS documents, for collaborative text editing for example), you might be interested only in the last operations per author and merge them to receive the latest document state:
Deletion
namakemono offers different forms of automatic or user-indented deletion, with various degrees of privacy as sometimes you do not want to keep traces of what data has been deleted by whom.
Garbage Collection
- Garbage collection only takes place locally, other peers do not need to be informed about this decision
Operations
- As already mentioned under "History" we can limit the maximum amount of operations per document and per author
- "Useless" operations are removed instantly as soon as the new one arrives
Documents
- Some documents are only retained when they are referenced by other documents, or if a reference they contain is still alive
- When references expire, documents or entire collections can be automatically garbage collected without leaving a trace
- See "Collections" for an example
Tombstones
- To delete a single document we can publish a Tombstone operation which will cause all operations for this document to be deleted
- This tombstone is sent other peers to inform them that we want this document to be deleted. To ensure the document remains deleted network wide, the tombstone should be kept until the document is "dropped" via garbage collection
- If we want to delete / tombstone the document we add the action field inside the header, no body is required
struct Header {
/// Needs to be set to "true" to tombstone this document
tombstone: Option<bool>,
// .. plus all other header fields
} - As soon as we've observed at least one tombstone operation inside a document we do not accept any other further operations
- If references expire as a result of document deletion then then any effected documents should also be deleted (see "Garbage Collection")
Extensions
Operations can be extended with certain features we usually want for high-level application concerns, like permission, encryption or defining data hierarchies. For this the header can be extended with additional informations.
Ephemeral documents
- Documents can be defined as "ephemeral", giving an expiry date after which all their operations should be deleted
- No tombstones are needed for this sort of deletion
- The following field is added to the header:
struct Header {
/// UNIX timestamp
delete_after: Option<u64>,
// .. plus all other header fields
}
Schemas
- Schemas are documents which can be used to verify that an operation or document following that schema is respecting a certain format
- Other documents can refer to that schema to indicate that they comply with this format
- We can do this by adding an extension field in the operation header:
struct Header {
/// Document View ID of the schema document
schema_id: Option<Hash[]>,
// .. plus all other header fields
} - Document view ids are lists of all operation ids we want to refer to to "reconstruct" exactly this version of the document. This is required for deterministic behaviour and supporting schema "migrations"
- We distinguish between "system schemas" and "application schemas"
- System schemas are determined by this very specification and usually serve low-level purposes like handling permissions etc. while application schemas are defined by application developers
- Application schemas are not further defined and can follow different sorts of schema / validation techniques, depending on the application data
- Nodes can identify schemas of documents and validate them accordingly, reject operations which do not follow the given schema correctly
Collections
- Sometimes we want to express multiple documents to be part of the same collection
- We can do this by publishing a Collection document and then adding an extension field in the operation of each document to assign it to this collection
- To create a collection document we publish a CREATE operation with the following
schema_idheaderschema_id:collections_v1- System schema identifier for collection documents
- To refer to this collection document we refer to it using the document id in the header
struct Header {
/// Document View ID of the collection document
collection: Option<Hash>,
// .. plus all other header fields
} - If a tombstone operation for a collection document was published, all related documents get deleted as well
- Collection documents can again refer to "parent" collection documents
- This allows for neat application patterns to design document and collection hierarchies
- Together with capabilities and collections we can express complex hierarchies of permissions. We can grant CREATE capabilities to allow publishing new documents in a collection, or think of groupings to express admins, roles and moderators etc.
 Collections help to structure application data, moderation roles, permissions and hierarchies
Collections help to structure application data, moderation roles, permissions and hierarchies
Capabilities
Capabilities are in the workings for 2024. Read our specification here: https://github.com/p2panda/access-control
Encryption
Encryption is mostly handled by decentralized continuous group key agreement (DCGKA) and our "Secret Group" specification which is heavily in the workings in our roadmap 2024, allowing offline-first PCS and FS double-ratchet encryption or "long-living" symmetrical encryption. You can read the paper https://eprint.iacr.org/2020/1281.pdf for more information around the approach we implement.
Replication
We use a set reconciliation protocol for efficient replication of p2panda operations. You can read the paper on our implementation here: https://arxiv.org/abs/2212.13567