Operations and Documents
While a lot in this document is still true for p2panda we've slightly adjusted our core data types to look a little bit different. You can read more about it in our namakemono specification. This section will be adjusted soon!
Most of the time, whenever we do something, we usually do it in multiple steps. For example when we cook a good curry for our friends.
We can think of many other examples, but all of them have one thing in common: Every step changes the state of things.
When adding salt to your curry it will become salty.
In p2panda we have a data type to describe a change of something. We call this data type an Operation. We can think about it as steps to achieve a task, like writing a message, cooking a meal or uploading an image.
Operations are the core of p2panda, they can come in different shapes and surely there will be many more to come in the future. Maybe you have some ideas for new p2panda Operations?
Operation Actions
Another way to look at Operations is to see them as a chain of actions we apply to something, for example updating our current username.
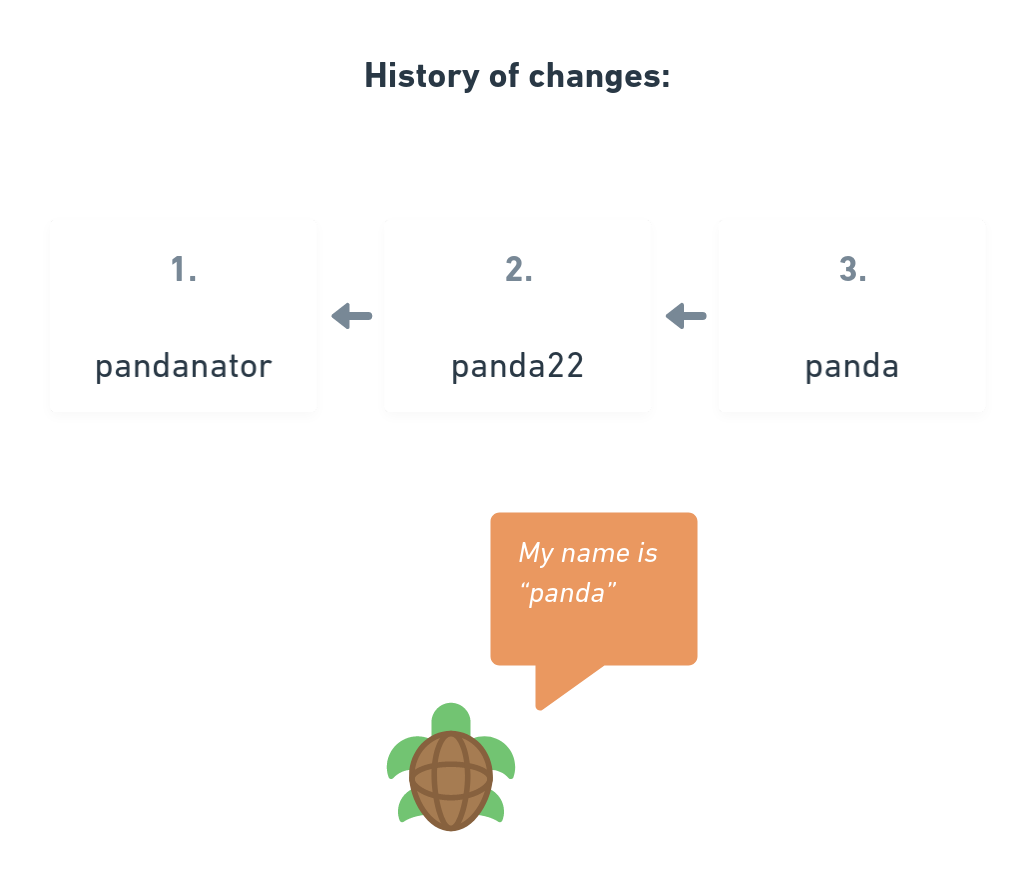
To describe this Operation we could say: “Every Operation updates our username” and this is also exactly how p2panda Operations work: We can define UPDATE Operations on data, like usernames! And there is a little bit more: The first Operation is always CREATE, to announce that there is a new username at all. And maybe you want to also DELETE it even again at one point.
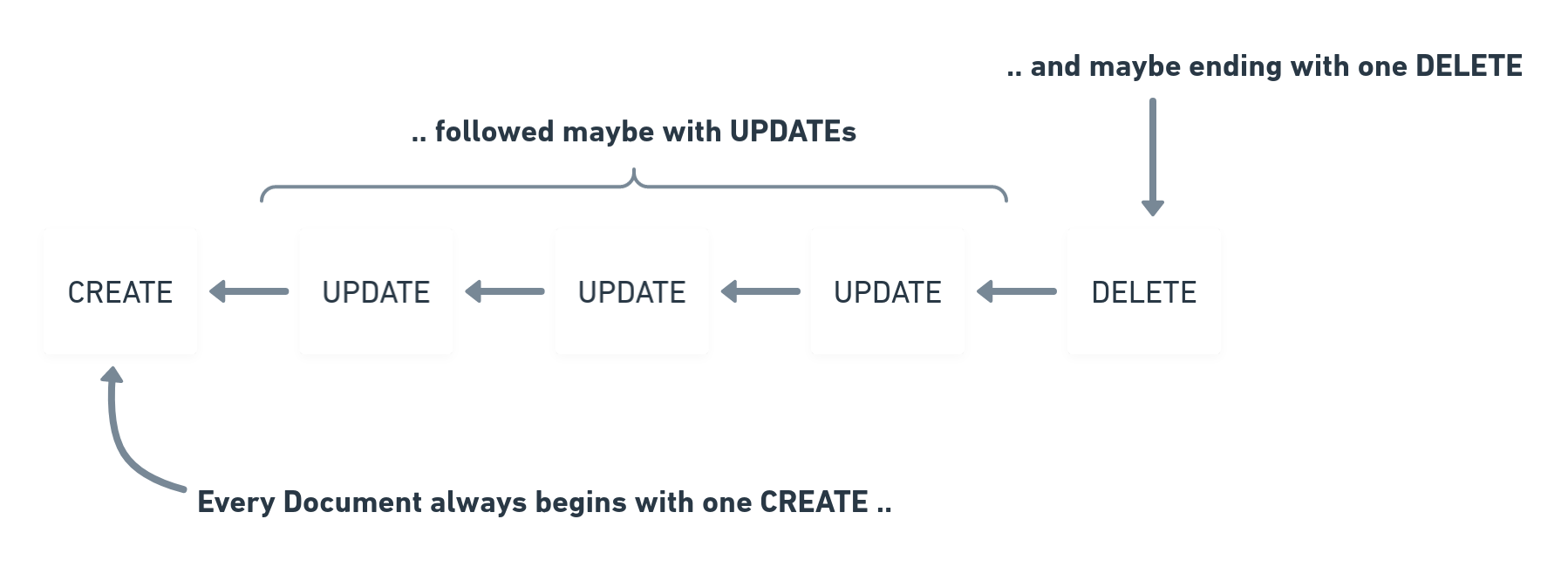
These are the three different Operation Actions p2panda currently has: CREATE, UPDATE and DELETE.
We write the Operation Actions in UPPERCASE just to make clear it is a defined constant and not an English verb in a regular sentence.
Documents
As we’re applying our Operations always to something we need a term for that. In p2panda we call this a Document. It is the result of a series of Operations!
For example: In our initial cooking scenario the series of Operations would lead to a Curry-Document, when updating our username it would lead to a Username-Document.
To create a new Document we send a CREATE Operation, to update it we follow with UPDATE Operations and then eventually we want to delete it with a final DELETE Operation.
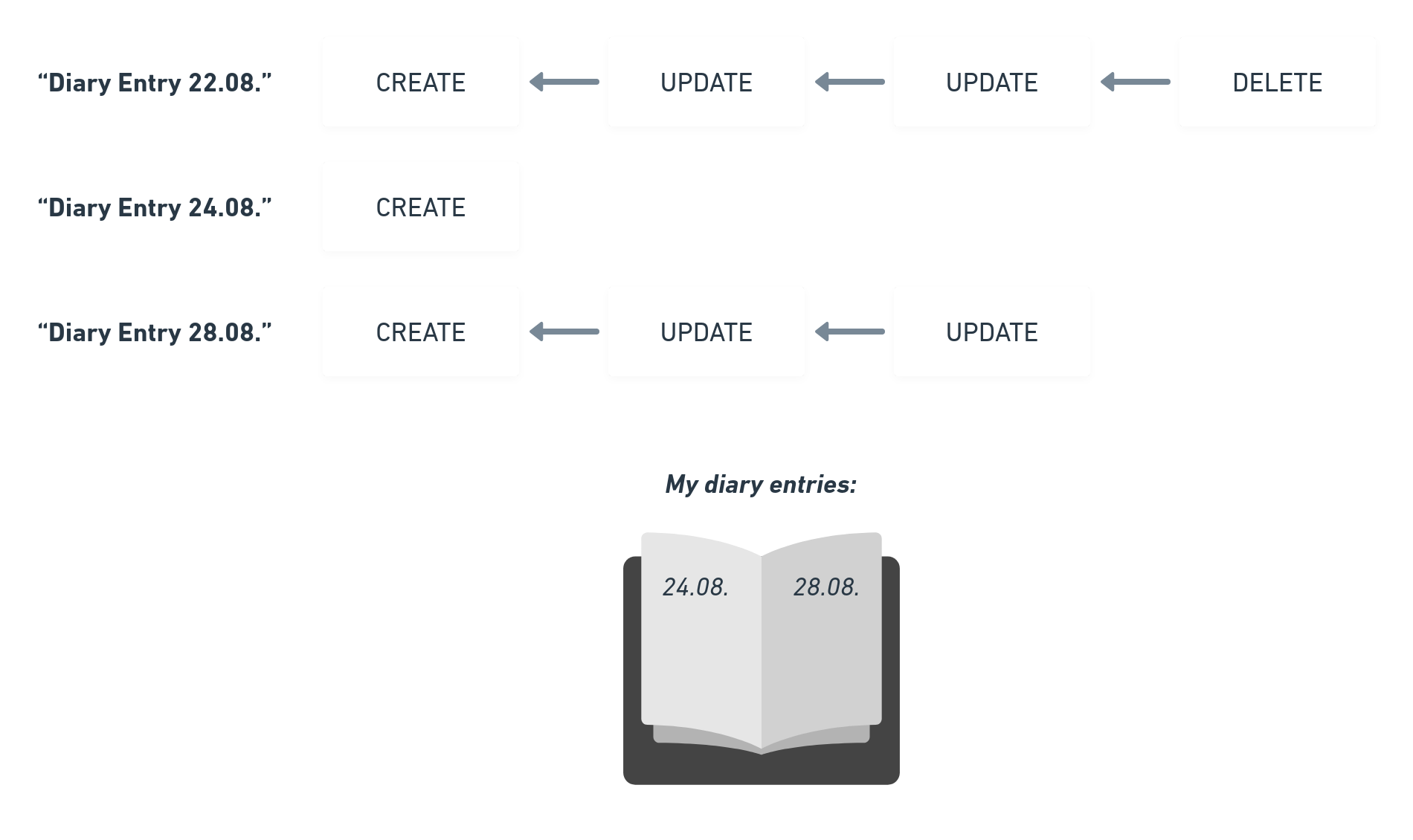
If there is a DELETE Operation in the Document then the complete Document can be considered deleted. In the following example we have Operations updating diary entry Documents. The user created already 3 Documents but deleted one recently.
Operation Fields
Documents are simple Key-Value Maps which means that there is always a name of a field connected to some value. An User-Profile-Document could for example look like that:
{
"username": "panda",
"is_cute": true,
"city": "Shirokuma Town",
"favorite_food": "Bamboo"
}
When we create a new Document with a CREATE Operation we have to make sure that all Operation Fields are given. For UPDATE Operations we only have to mention the fields we want to change. DELETE Operations do not need to mention any fields as we’re simply just telling everyone that we want the Document to be deleted.
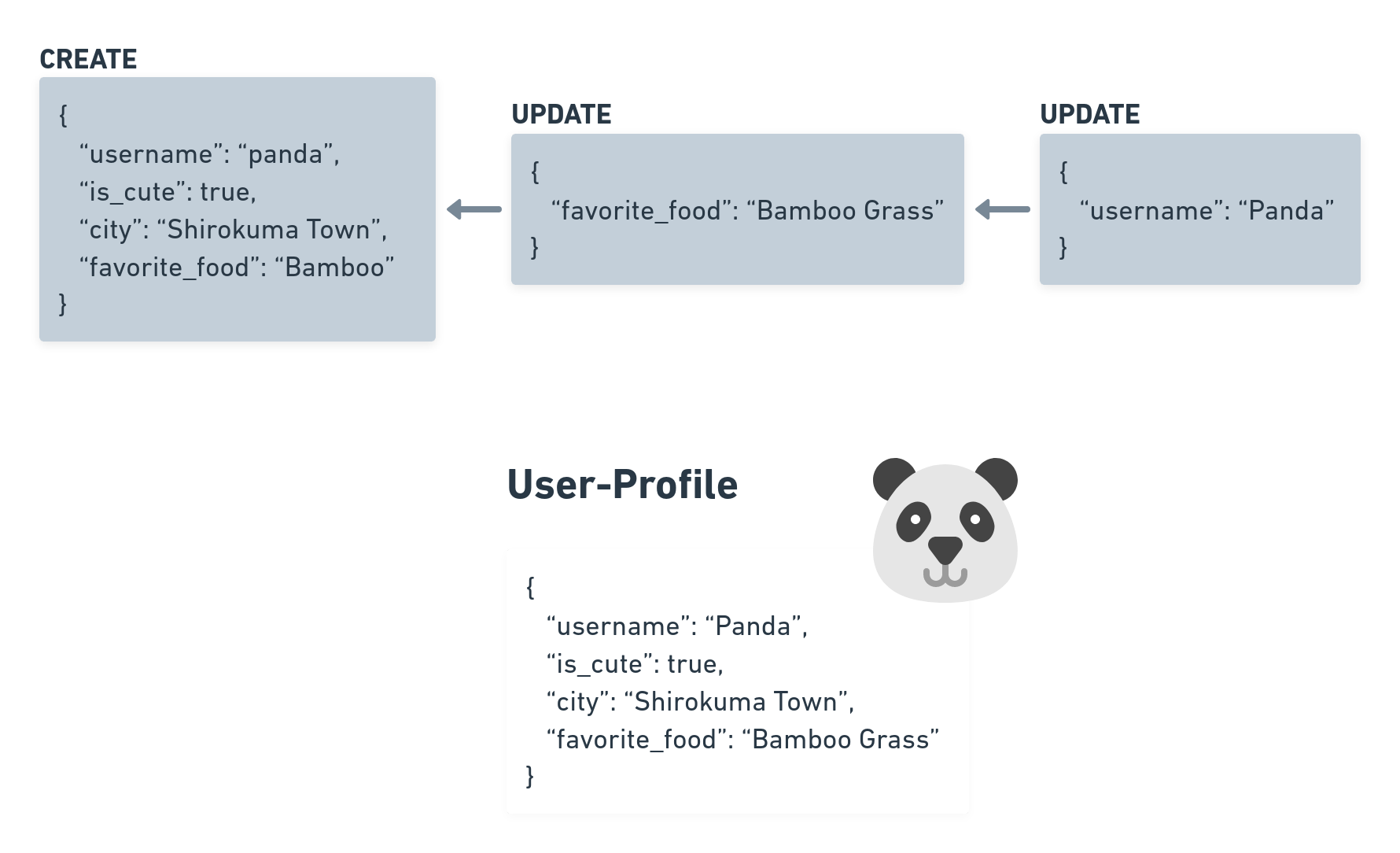
With this we can imagine more complex Documents which can contain many different sorts of fields!
Operation Field Types
In the above example we could already see two different sorts of Operation Values. panda and city and favorite_food were strings, but is_cute was a boolean! p2panda currently supports the following basic Operation Field Types:
strStrings of any length, like”Hello, World!”boolEithertrueorfalseinti64 integer numbers, like511or829187401floatf64 float numbers, like12.52or-255.12
There will surely be more Operation Values in the future! An array would be good for example.
Next to the basic types there are also Relations. We will cover them in another chapter.
Schema
Our User-Profile-Document has a specific shape which needs to be fulfilled:
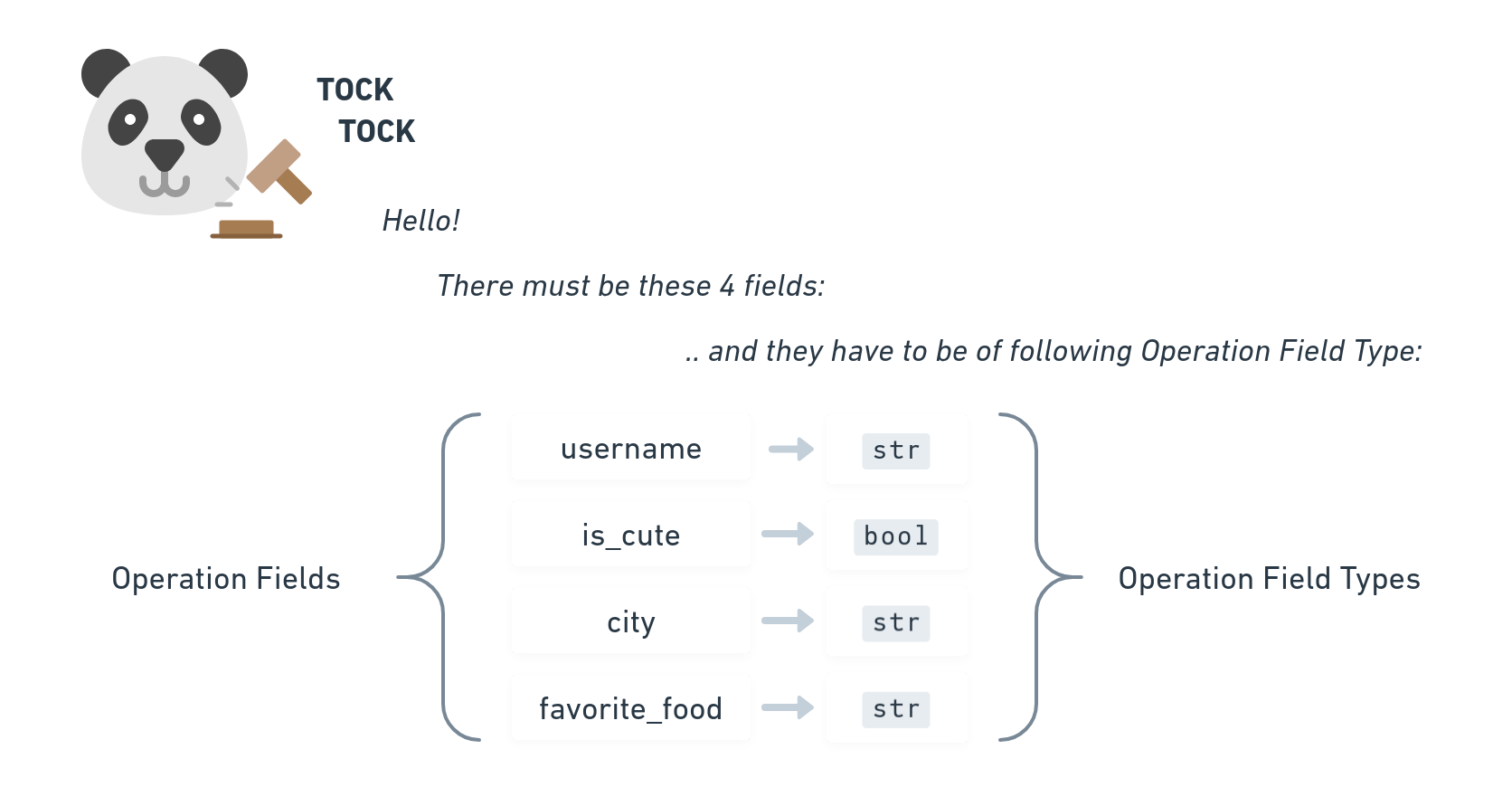
Everyone in the p2panda network can define the shape of a Document and announce it in form of a Schema. Now users can refer to that Schema by using its identifier, the Schema Id. Whenever they publish an Operation with a certain Schema Id, the Operation needs to match the fields of the given Schema.
Currently schemas prescribe only the name and type of a field, but later we will have regex, min, max and many other validation methods as well, to restrict the data even more to a certain shape.
Encoding
After we’ve created an operation we usually want to publish by sending it to our node. For this we take the following steps:
- Encode the operation
- Create a new Bamboo entry and use operation as its payload
- Sign and encode the entry
- Send entry and operation to node
For Operations the specification prescribes an Operation Format. Here is an example of how to format an CREATE operation:
[1, 0, "profile_0020...", { "username": "Panda" }]
We can see here that Operations are encoded as an array with a couple of fields inside which might already look familiar to us:
- The first field indicates the Operation Version. It helps us to understand what encoding we can expect from the following data when we receive a new Operation from somewhere. It is set to
1here which is the first version. - The second field indicates the Operation Action we already talked about before.
0stands for CREATE,1for UPDATE and2for DELETE. In this example we’re looking at a CREATE Operation. - The third field indicates the Schema Id we also talked about before. In the example it's shortened, but we can imagine that this is where we set what schema this operation wants to fulfil.
- The fourth and last field here are the Operation Fields with the actual application data we want to publish.
This Operation Format will be now encoded as CBOR bytes which is a well known and slim encoding format. This is how it would look like (bytes represented as hexadecimal numbers):
84 # array(4)
01 # unsigned(1)
00 # unsigned(0)
6F # text(15)
70726F66696C655F303032302... # "profile_0020..."
A1 # map(1)
68 # text(8)
757365726E616D65 # "username"
65 # text(5)
50616E6461 # "Panda"
We would send this data to a p2panda node, of course without the comments and with a complete schema id:
840100784C70726F66696C655F3030323034336233653664613933366633633937663732373666303766363562303361303632373235666436363963323563373738653665653165336136333565393264A168757365726E616D656550616E6461
You can decode this data again using the https://cbor.me playground. Just paste the hexadecimal string into the right area and click on the left-facing arrow button to decode the CBOR data. It also works the other way around!
Operation Id
Whenever we encode an Operation and sign it with an Bamboo Entry we sign the data and make it immutable from that point on. If we would change the Operation now afterwards, the Signature would break and we would need to reject this Operation as something invalid.
Bamboo Entries seal Operations for us. They are the data type which makes sure that nobody tampered with our data after we’ve sent it out.
Since we used an Bamboo Entry to get this security and immutability we also receive a unique identifier after signing, encoding and hashing it: The Hash of the Entry becomes our Operation Id. It is an unique sequence of numbers which will indicate that we exactly want to refer to this Operation.
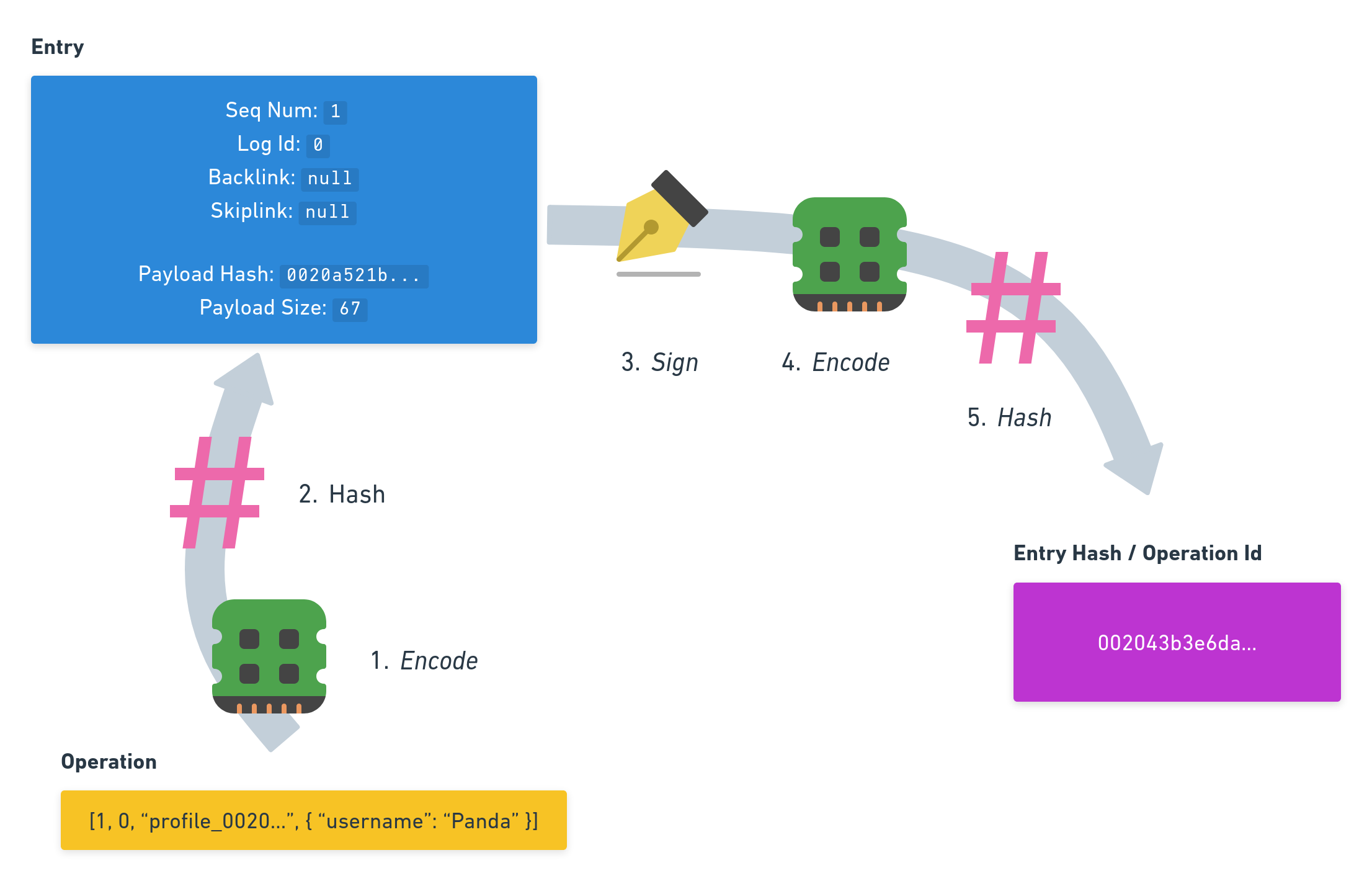
There are a couple of steps involved to achieve this: The Operation gets encoded as we’ve just learned, then hashed for the Bamboo Entry where it will be inserted as the Payload Hash. The Bamboo Entry gets signed, encoded and then hashed as well. That resulting Entry Hash will be our Operation Id!
Hui! Actually, if we want to be really precise: Before signing the Entry it already gets encoded once, just without the Signature. After signing it it gets encoded again this time with the Signature.
Document Id
This is a fairly short section, but an important one:
Every Document we’ve created in p2panda has an unique identifier, the Document Id. Where does it come from? It is the Operation Id of the CREATE Operation which created that Document! This works because there will always only be one CREATE Operation per Document.
Document Views
So far we’ve only talked about creating Documents, but how does the Operation need to look like if we want to update or delete them?
Similar to how you would refer to a row in a SQL database by its unique identifier we have to specify which document we want to update or delete.
In p2panda everything can happen, since it is a decentralised system, so we need to be prepared for many users updating a document at the same time. Or someone updated something, but did it when they were offline! As a thought experiment, let’s imagine multiple updates to the same document:
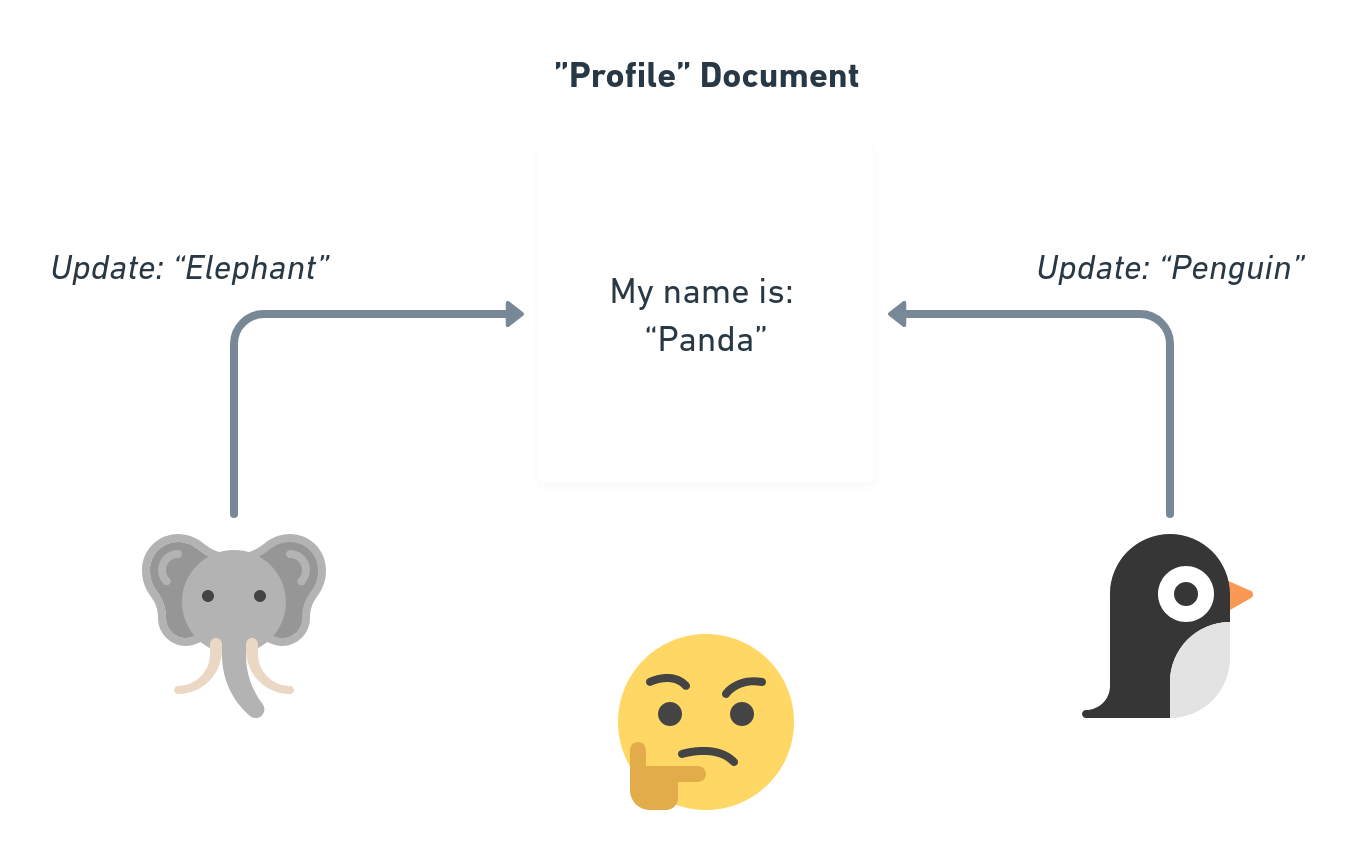
Who was first? That’s hard to tell! Usually we would just say that who has written last to the database will win. If Elephant was slightly later sending its change it would say My name is: “Elephant”. In p2panda we don’t have that central server though which just knows who arrived later. We have many independent nodes where the updates might arrive differently. On the node of Penguin it might say My name is: “Elephant” and on the node of the Elephant it’s My name is: “Penguin”, because the foreign updates arrived later due to the networking delays .. This is horrible!
To fix this problem we need to know what Penguin and Elephant did see when they updated the document. What was their last point of view when they wanted to update something? Maybe the Penguin only saw the original “Panda” profile and applied its changes, but Elephant saw later that Penguin made an update and applied its changes afterwards?
For this we ask the user to also publish a previous field inside of every Operation if they want to update or delete a document. Inside this previous field they can specify what the latest Document View was what they knew about.
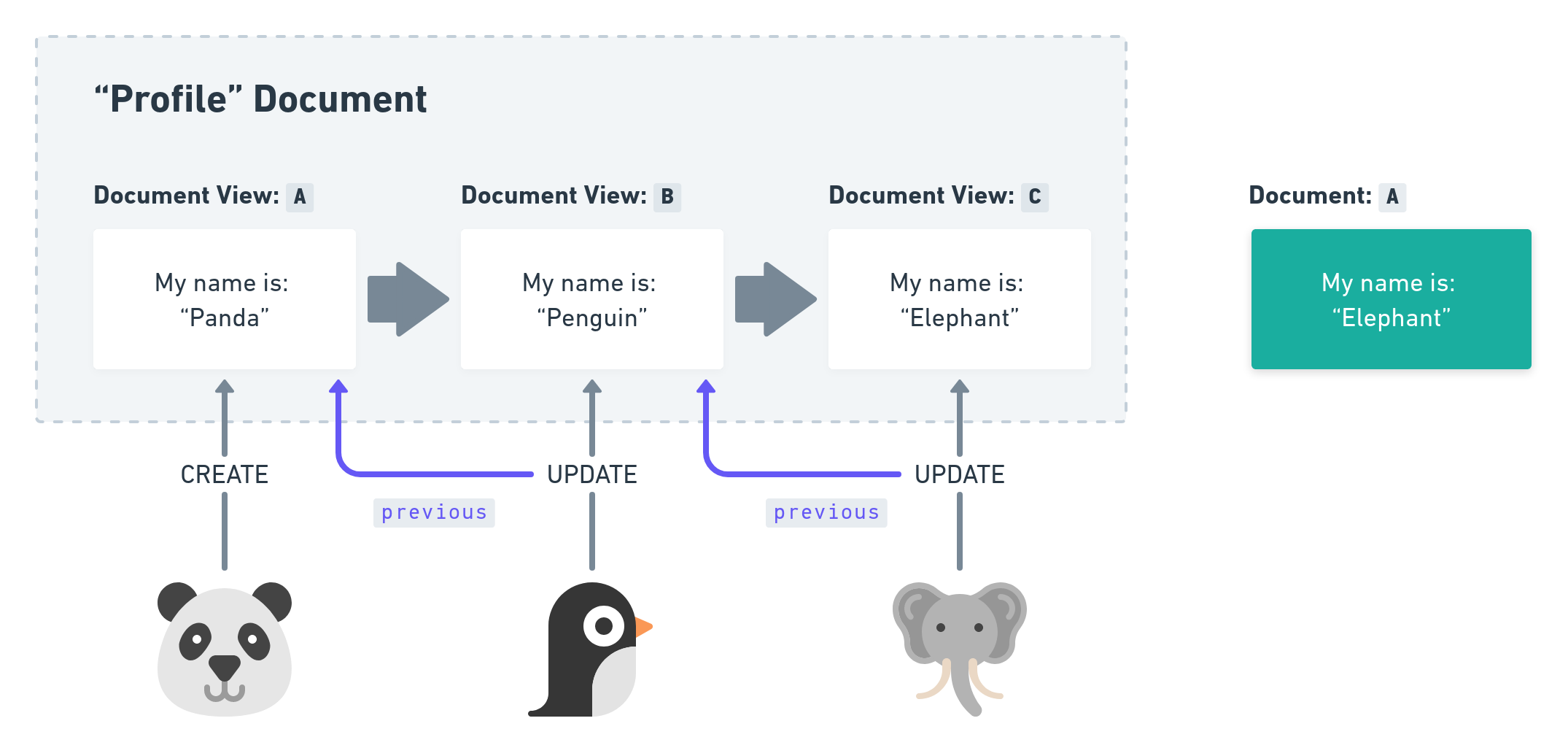
Whenever an Operation takes place, it will generate a new Document View. We can understand them as a version or revision of our Documents. When sending a CREATE Operation there is one Document and one Document View, both will contain the same data, as so far there is only one version of it.
After we’ve sent an UPDATE Operation things get more interesting: We still only have one Document, containing the latest changes, but gain one more Document View! The Document will always contain the sum of all changes, but we keep track of its history with many Document Views.
In our Elephant / Penguin example we can see that indeed the Penguin applied its UPDATE Operation onto the original Document View of the Panda, followed by the Elephant. So what is the content of this Document? It is My name is: “Elephant!. 🐘 How can we be sure? It is because we follow the rule Last Write Wins and with the help of the previous fields we can trace back who was last.
We encode UPDATE Operations like that:
[
1,
1,
"profile_0020...",
["0020..."],
{
"username": "Penguin"
}
]
Note that the Operation Action changed to 1 now, which indicates that this is an UPDATE Operation now. Also there is a new field appearing after the Schema Id, which is the previous field. It contains the Document View Id where we want to apply the update to.
UPDATE Operations do not require us to mention all Operation Fields anymore, we only need to write the ones we want to update.
DELETE Operations also have a previous field: We have to mention from what point on we want this document to be deleted. Currently it will just cause the Document to be removed, but we will learn later that there are some interesting features around this sort of behaviour.
The encoding of DELETE Operations is similar, just that the Operation Action is 2 and we don’t need to specify any Operation Fields since we just wanted to say that we would like to delete the document:
[
1,
2,
"profile_0020...",
["0020..."]
]
Let’s look a little closer at this previous field: It is an array which contains a Hash string again. The Hash itself is the Id of the Operation we saw last, but why does it need to be an array of them?
Here it gets really interesting and we might even talk a little bit about graphs.
Graphs are structures made of vertices and edges. You can probably imagine many graphs in your daily life: Public traffic networks are graphs, your family tree is a graph and a network of connected computers is a graph! When we say Graphs we usually mean a more abstract / mathematical idea of them, but still it helps us a lot to solve cool problems: For example finding the shortest path between two points inside of it.
Operation Graphs
In our above example Penguin and Elephant behaved very well: They applied their changes correctly after each other. But what if Elephant would have applied its change at the same point as Penguin? We are back at square one.
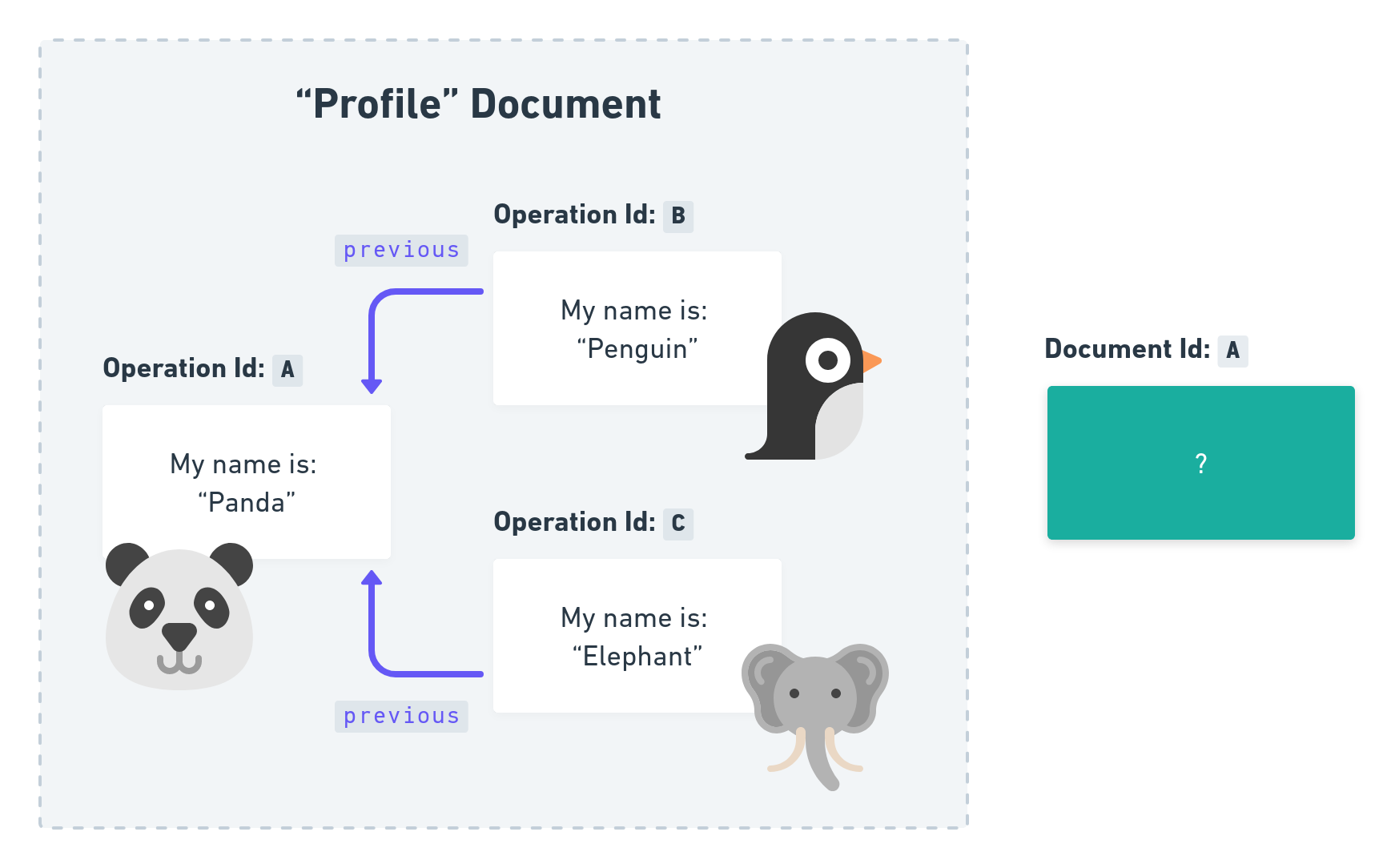
We end up with a situation where our Document suddenly has two different ends!
That’s a graph with three vertices A, B, C and two edges (the two previous links)!
Both Penguin and Elephant edited the document at the same time! We can even proof it with the previous fields both pointing at Document View A!
Not time in the sense of ⏰ 11:34:58, but more in 🔢 causal order
What is the state of the Document now? Does it contain My name is: “Penguin” or My name is: “Elephant” if we request the latest version?
This situation we call a Merge Conflict. It occurs when two users edit the same Operation Field at the same time. To resolve it we need a Conflict Resolution strategy and it is actually fairly simple: In p2panda we simply let the Operation win with the higher Operation Id!
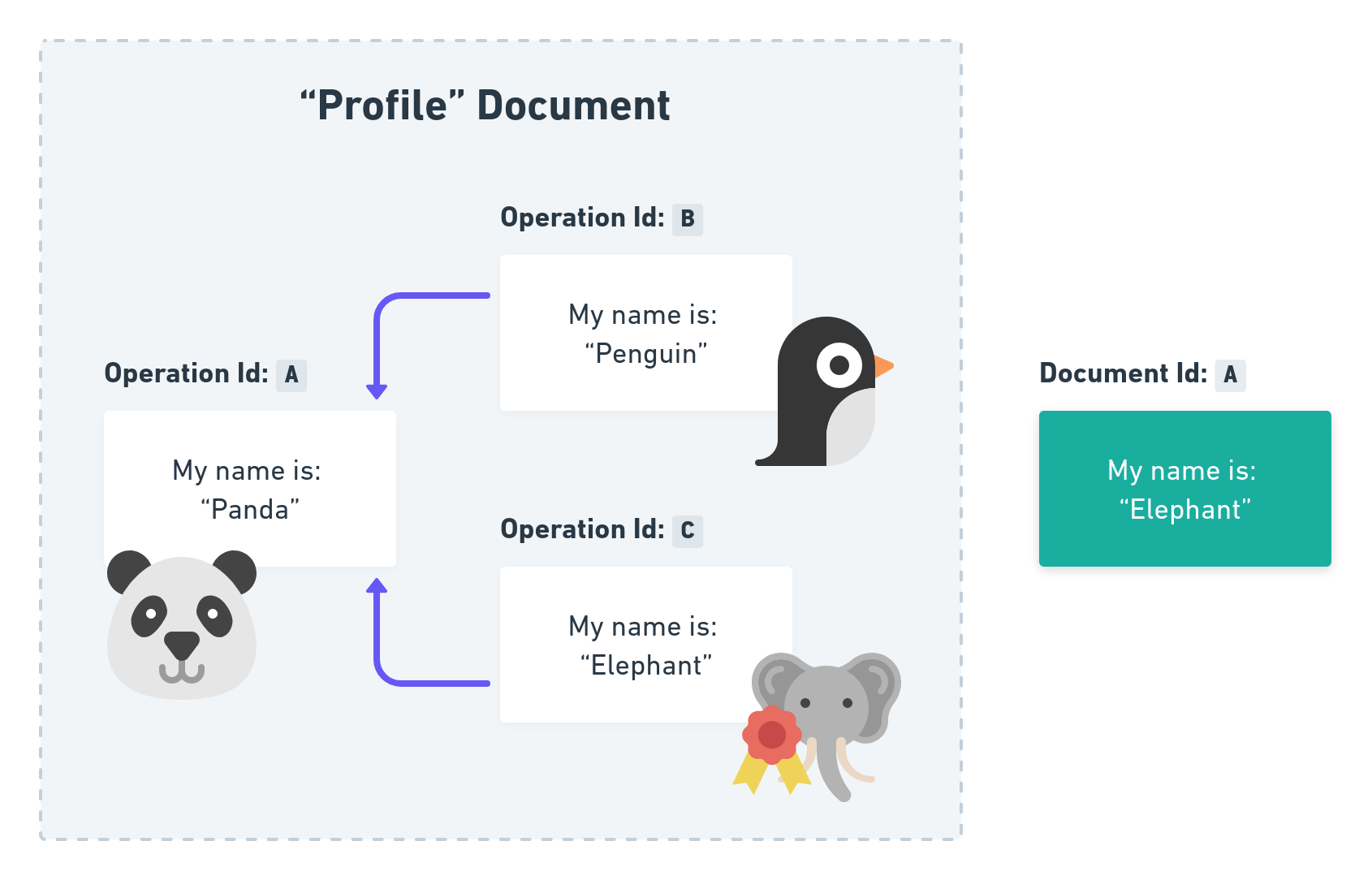
In our example the Operation Id C is higher than the one of Operation Id B. So the Elephant will win! The good thing about this solution is also that all nodes which will see these Operations will decide for the same outcome. This makes the Conflict Resolution Strategy deterministic.
Is this fair? Since Operation Ids are based on Entry Hashes which are unique it is randomly decided who will win. This is maybe arbitrary but more fair than sorting the winner by timestamp, since you would be able to make up a higher timestamp in a decentralised protocol.
With these features we made Operations a Conflict-free Replicated Data Type (CRDT). That means: We can make updates on arbitrary documents but never have to worry about merge conflicts which will make the whole system fail. With these two simple rules we can already solve it: 1. Operations are ordered in an Operation Graph based on their previous fields 2. Conflicting updates on the same Operation Field are won by the Operation with the higher Operation Id.
There is a lot of theory around CRDTs, but really, it's basically these two rules you need to define to get one: How do you order data and what is the rule when something conflicts?
Do you wonder what the cool algorithm is which reconciles and reduces the operation graph in the way we just described? If you get up in the morning and you are tired, you might be too slow to remember if you need to put your socks or underpants or pants or shirt or pullover on first. With Topological Sorting we can sort Dependency Graphs in a way where they will tell us what we have to do first before: Your socks are not dependent on anything, you can put them on whenever, but you should put on your underpants before you put on your pants for example! This is exactly what p2panda does: We traverse the operation graph with a Topological Sorting algorithm, bringing all operations into one ordered list, based on their dependencies. Where do we get the dependencies from? The previous links of course!
We have missed out on one initial point though which actually was the reason why we started this section: Why is previous an array field? Let’s imagine there is someone new who wants to apply an UPDATE Operation on the Document. Where would this user apply this update to? On the Penguin Document View or the Elephant Document View? The correct answer would be: On both of them, because this is the latest state of the Operation Graph, and for this we need an array.
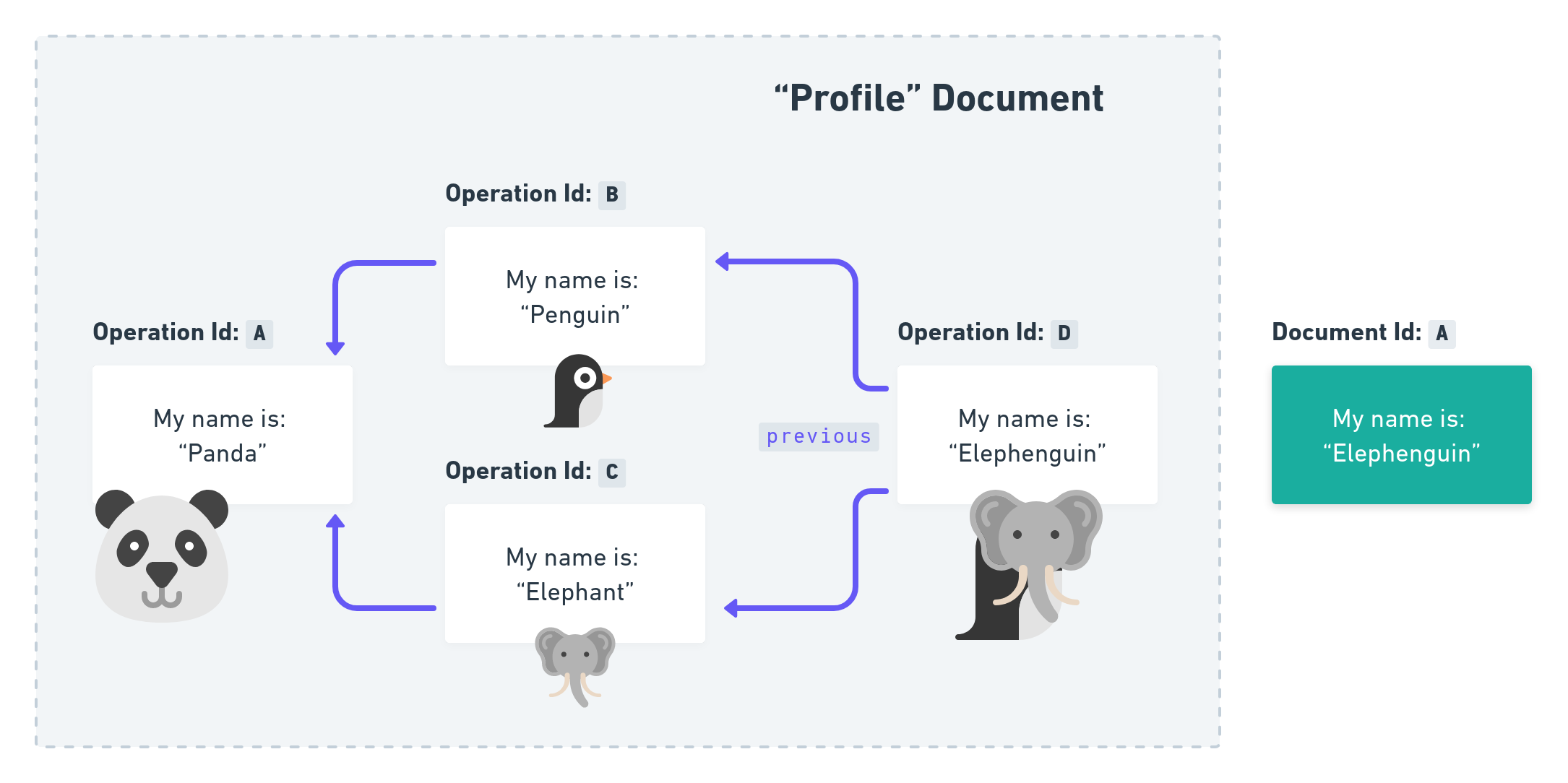
This new animal in town creates a new Operation with Id D and relates to both Operation B and C in its previous field. We call this a Merge.
We can use a Merge as a strategy to manually resolve a Merge Conflict. But it’s not like this is their only purpose. It is also just describing your perspective on the Document: In the moment you wanted to make an update you have been aware that there were two concurrent changes being made before and you just wanted to note that.
As already mentioned, solving Merge Conflicts is only important when we write to the same Operation Field, if we’re concurrently writing to different fields then we also don’t have a conflict. Let’s look at this example:
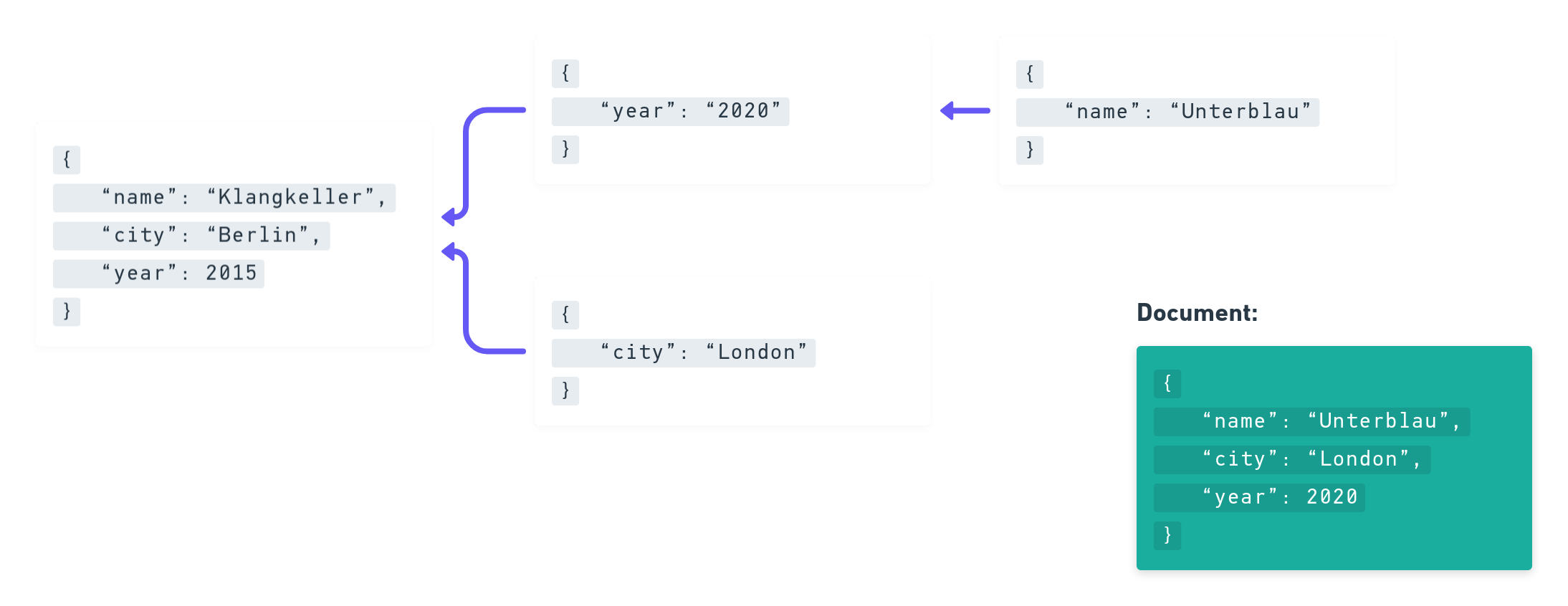
We can see that Operation Graphs are quite powerful. In a way we can see them as a tool which helps us to describe what we knew about the world when we decided something. In p2panda these views can be quite different: Some users might have been applying changes for weeks without connection to the internet. As soon as they went back online and synced up their changes with the others, we can see in the Operation Graph that a lot happened while the offline user made all of these changes. But this is not a problem, thanks to CRDTs.