Networks
In p2panda we need at least two participants to call it a party: We need a Client and a Node. Okay, they don’t sound like the most fun party guests, but we promise you, they are cool!
Clients
Clients are programs which read or write data from Nodes. To write data they need to sign it before, which means that they have to also hold a Private Key somewhere safely.
Reading
Reading from them is fairly easy: We just need to send a GraphQL query like that:
{
all_mushroom_0020... {
documents {
fields {
title
edible
description
latin
}
}
}
}
If our Node knows something about mushroom Schemas, then we would get a response now. The Client can render the result in a user interface or process that information somehow.
If you haven’t read about Schemas yet, we can recommend reading the previous learn chapter about Operations and Documents. Or you might even want to directly create your own Schemas in the tutorial!
Not every Client needs to be used by a human. Clients can also be automated bots which operate in a p2panda network.
This already tells us something important about Clients and Nodes: Nodes are the part of the network which store the data for us. This is why we can query something from them as Clients!
Writing
Since the data lives on a Node, we should also send our new data to them, whenever we create something. This again can be done with a GraphQL mutation, for example like that:
mutation Publish($entry: String!, $operation: String!) {
publish(entry: $entry, operation: $operation) {
logId
seqNum
backlink
skiplink
}
}
We’re sending a Node an Entry and Operation, these are the essential data types of p2panda.
The node optimistically responds to us with data containing logId, seqNum, backlink and skiplink, which are arguments we can use to create our next Entry.
Entries need to be signed by a Key Pair which only the Client knows about before it is being sent to a Node. This Signature proves that the Client was the original creator of this Operation and ensures that it can not be changed afterwards anymore.
You can read everything about Entries, Key Pairs and Signatures in the regarding Bamboo Entry learn section. If you’re curious about Operations, then we have you covered with the Operations & Documents learn section.
Whenever a Client wants to write data to a Node, it needs to keep the Private Key of the Key Pair safely stored. This is an important trait of Clients: They are the holders of a private key. Nodes will never know about them!
Nodes
Nodes do much more than Clients! They are the actual participants in the network, validate the data, store it, materialise it, find other nodes to distribute the data even further.
Validation
Every Node checks the Entry and Operation the Client signed, encoded and sent to it. It validates a couple of things:
- Was the Entry and Operation correctly formatted?
- Is the Signature of the Entry valid?
- Does the Operation really belong to this Entry?
- Did the Operation fulfil the claimed Schema?
- .. and much more!
Persistence
After all the data has been checked it finally can be stored in the database of the Node. Nodes are the **Persistence **layers of the p2panda network.
The p2panda specification does not prescribe how you want to store the data. In our reference implementation aquadoggo we’re using PostgreSQL or SQLite, but you could also take something else if you want to build your own Node.
Materialisation
The data the Node received and stored from the Client is still in a very raw form and needs to be processed. We did not query Operations but Mushrooms in your example above!
Operations just describe changes of data but not the final state of the data in the end. These final results we call Documents. This is also the data we want to query as a client. But first our Node needs to prepare them to look like that!
To get from raw Operations to Documents, we apply Materialisation. This is where the heavy work begins: Nodes need to look at all Operations which form Documents together, run the Materialisation algorithm and store that state in the database again.
This is one of the main reasons why p2panda separates Clients from Nodes: Materialisation can take time and resources from your computer and especially in Browsers it might get slow. If we separate the processes from each other we get a lightweight, fast Client (and a happy Human using it) and move the work into the background to the Node.
Discovery
Nodes are so cool, they can do even more! They walk around during the party and try to see if there are other Nodes hanging around.
This process we call Discovery, it basically means that Nodes try to find other Nodes inside of the network.
Discovery is quite tricky and one of the main challenges for p2p networks. The reason for this is that the internet has grown faster than expected, leading to a shortage of IPv4 addresses. Usually our smartphones, laptops, computers, etc. are all connected to the local WiFi network - but that would mean that each of them would need to get an unique IP address, and these are very rare! To circumvent that problem NAT traversal mechanisms have been invented which translate one global IP address to multiple ones in your local network. Because of this translation it is hard to find out from the outside how we can connect to that smartphone behind the NAT. At the end of the day, we want to build a peer-to-peer network, we want to directly connect to that device!
There are different techniques to achieve this, on a local network we can simply just broadcast a message and say something like: “Hello, I’m a Node and I’m here”. Other Nodes will pick these messages up and learn about that Node. That would be the equivalent of screaming every 2 seconds at a party, telling everyone else that we’re still there. Sounds quite annoying, but it works! This technique is called mDNS, or Multicast DNS.
If we’re leaving the local network and we still want to discover other Nodes it gets a little more tricky. Usually we can solve this with some sort of dedicated Signalling server (or a couple of them), which help us to announce that our Node entered the network. Other Nodes can look these announcements up by calling that server. We can think about them a little bit like telephone books where we can look up phone numbers.
Another technique of getting to know some other Nodes at a party is to enter it with already knowing one Node friend who will be there. That Node friend can tell you about the other friends they know about. If you continue asking all friends about their regarding friends you will probably end up with knowing all Nodes at the party. This approach is based on a Gossip Protocol and does not need a central server. But you need to know someone already before you enter the party!
In our current aquadoggo implementation we use mDNS for local networks and a rendesvouz server to find other nodes on the internet. You can read more about it in our specification.
Replication
Okay, but now back to our Node! What do Nodes do when they finally meet each other? They start Replication! This is the process of sharing the data they know about.
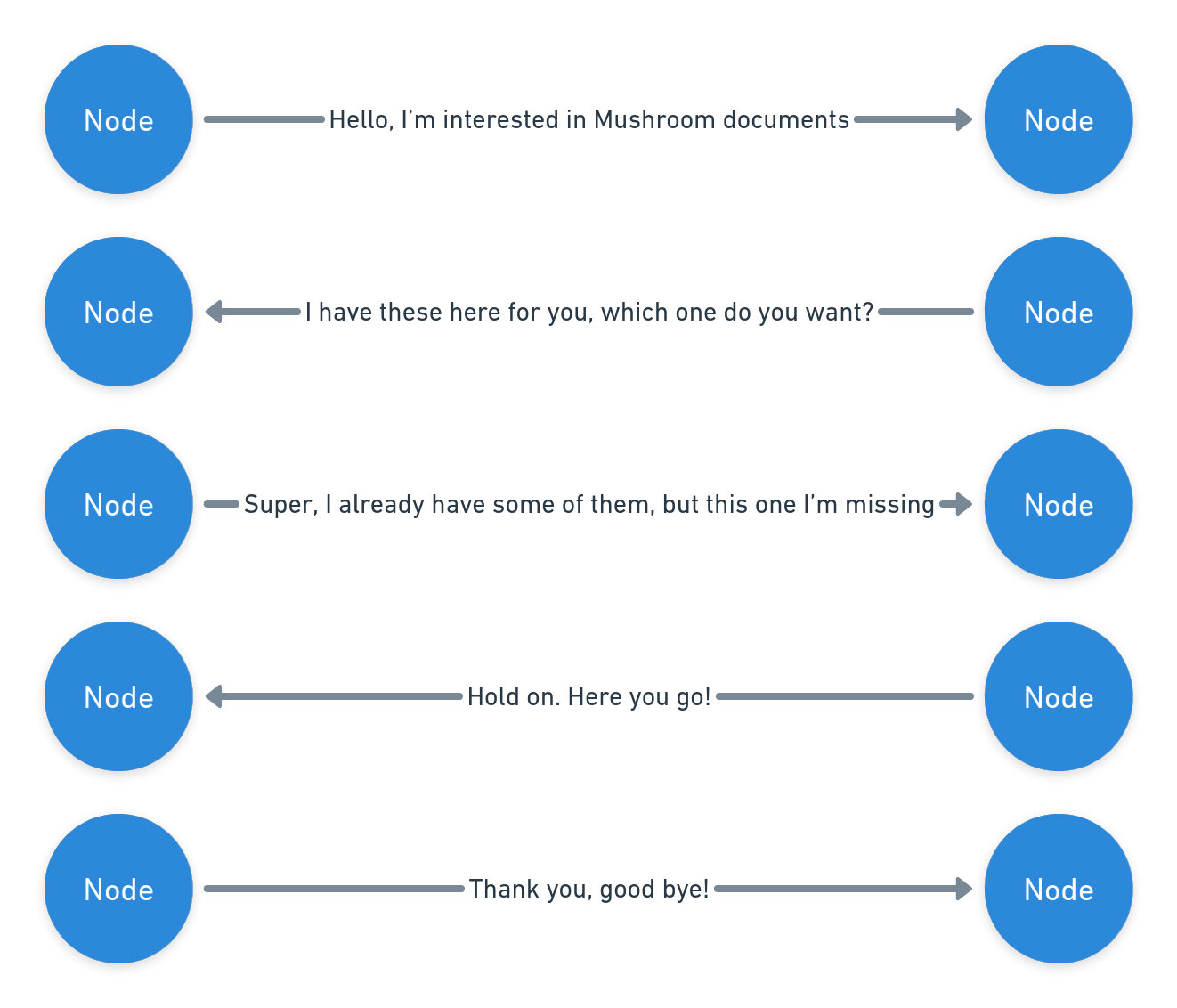
Replication makes sure that data spreads across the decentralised network. This means that not all Nodes know everything at the same time. They might only get to know some data later, or maybe never! This makes p2panda an Eventually Consistent Database.
Read about our replication protocol in our specification.
Decentralisation & Federation
We’ve seen now the relationship between Clients and Nodes. Clients are the creators and consumers of data while Nodes take care of the rest.
Since Clients only need to talk via GraphQL to a Node they can be easily implemented without much effort.
We can now imagine all sorts of clients: An mushrooming app, a computer game or a cool festival tool to set up events. They can run as web applications in the browser or can be implemented as native applications, also running on mobile phones.
But how do we implement a Node? The good news is: There is already one reference implementation called aquadoggoand since Nodes are agnostic to the data they process, you probably can just use this one. It gets even better: Nodes can support all sorts of applications as long as they know about the Schema the application needs!
This gives us quite many options now on how to deal with the Node: We can host it on a server on the internet and simply just allow many clients to talk to it. This is what we would call a Federated Node. It is a Node shared with many clients.
We could also host the Node directly on our computer, for example just as a running program, or even a background process which automatically launches as soon as we’ve started our computer. This is what we would call a **Decentralised Node **as it is not shared and runs locally on your device. But this would require you to understand quite a bit about computers and we can’t assume that everyone will do the same.
We can also embed the Node directly next to the Client and ship it all bundled in one program! This is the easiest method for the users, as they can just install the application and will get a Node for free without worrying too much about it.
With cool frameworks like Tauri we can easily embed aquadoggo and have a JavaScript web view Client in front of it.
For whatever Network Topology you decide: All Nodes will always be able to communicate to each other whenever they want to. It does not matter if you decided to host yours in a federated or decentralised manner.
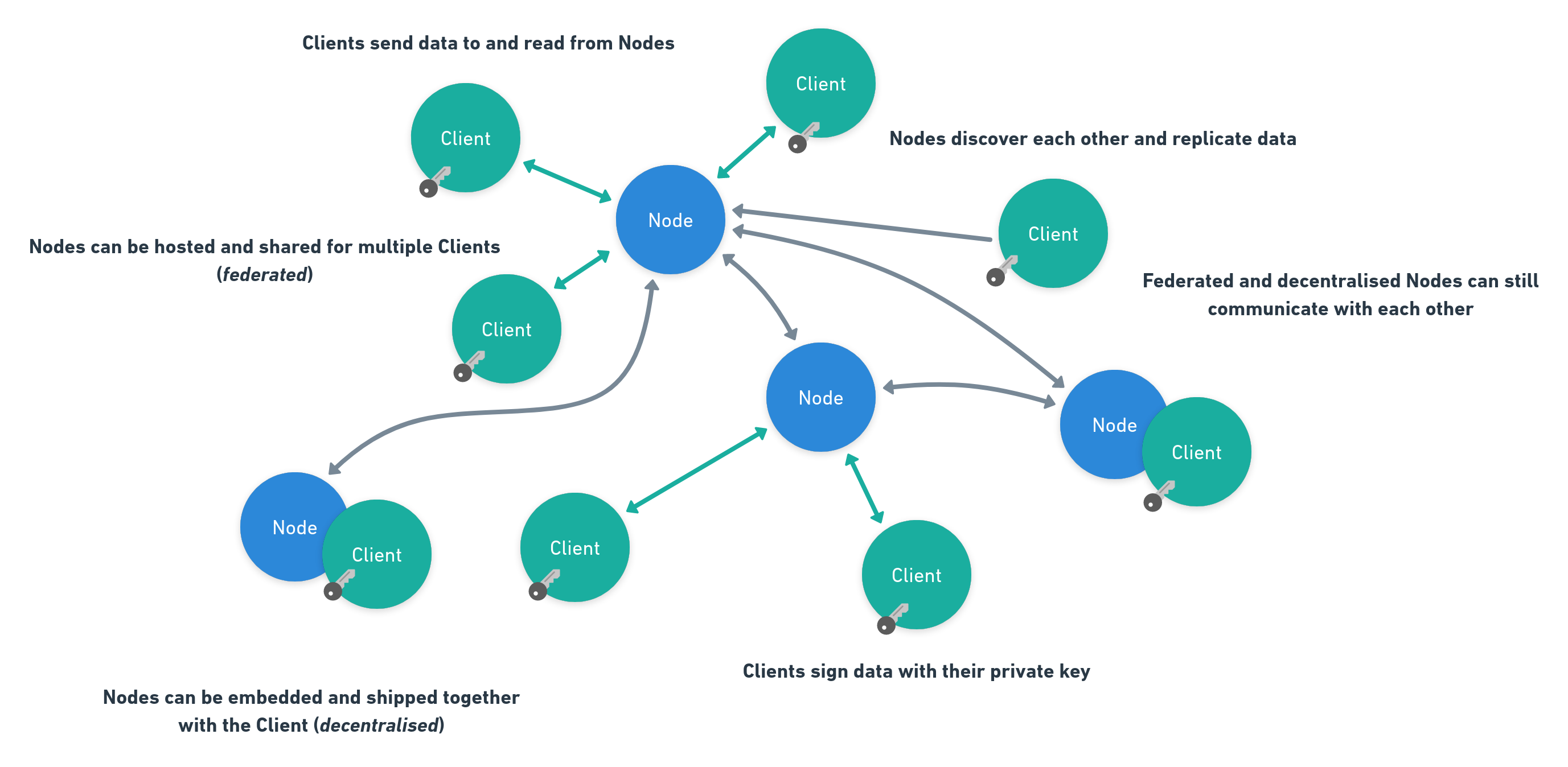
Similar to the Replication and Discovery, deciding on an approach has different implications: Sharing a Node with others comes with much more responsibility but easier access. Users can just open a website and directly interact with the p2panda network! Having your own local node is practical if you want to be able to be offline and still use your Client. Also you will have your data in exactly your place.